TECHNICAL ASSET FINGERPRINT
f7392beb49273be07c423ae8
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: healer-alpha-free VERSION 1
RUNTIME: free/openrouter/healer-alpha
INTEL_VERIFIED
\n
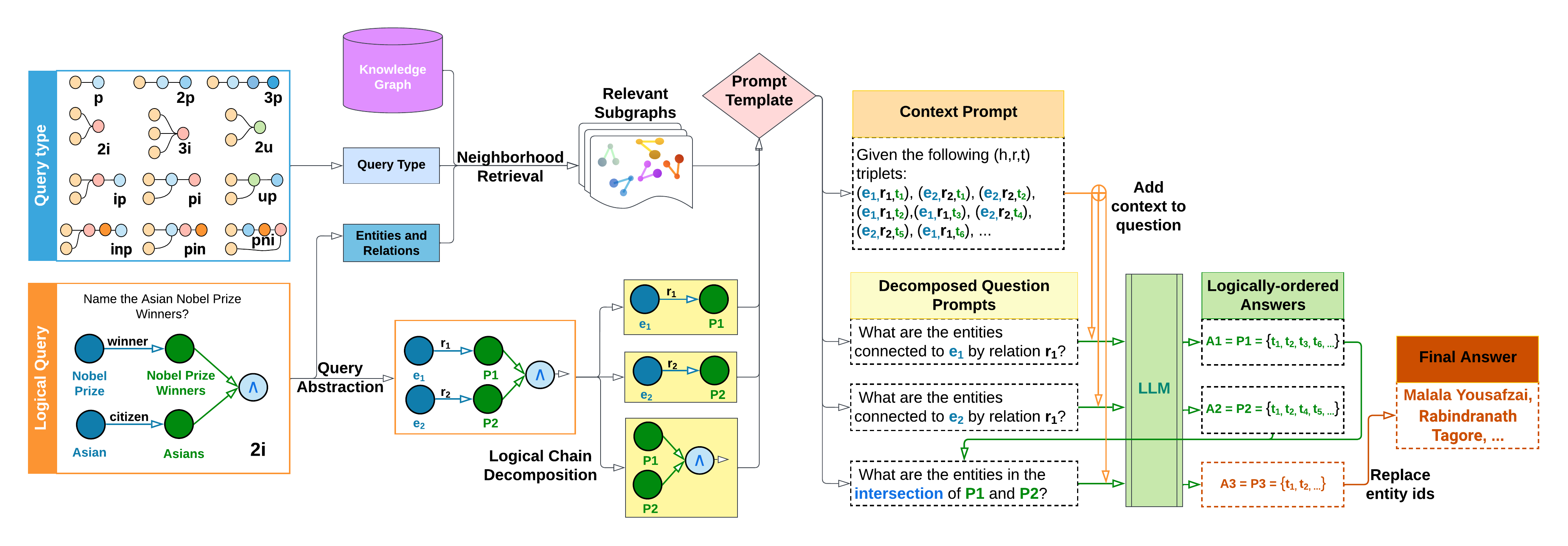
## Diagram: Knowledge Graph Query Processing System
### Overview
This image is a technical flowchart illustrating a system that processes natural language logical queries by decomposing them into sub-queries, retrieving relevant information from a knowledge graph, and using a Large Language Model (LLM) to generate a final answer. The diagram shows a multi-stage pipeline from query input to answer output.
### Components/Axes
The diagram is organized into several interconnected blocks, flowing generally from left to right.
**1. Query Type (Top-Left, Blue Box):**
* **Label:** "Query Type"
* **Content:** A grid of 12 small graph pattern icons, each labeled with a code:
* Row 1: `p`, `2p`, `3p`
* Row 2: `2i`, `3i`, `2u`
* Row 3: `ip`, `pi`, `up`
* Row 4: `inp`, `pin`, `pni`
* **Function:** Represents different types of logical query structures (e.g., projection, intersection, union).
**2. Logical Query (Bottom-Left, Orange Box):**
* **Label:** "Logical Query"
* **Content:** An example query and its graph representation.
* **Text:** "Name the Asian Nobel Prize Winners?"
* **Graph:** Two parallel chains converging with an intersection symbol (∧).
* Chain 1: Node "Nobel Prize" --[winner]--> Node "Nobel Prize Winners"
* Chain 2: Node "Asian" --[citizen]--> Node "Asians"
* **Label:** "2i" (indicating a 2-intersection query type).
**3. Knowledge Graph (Top-Center, Purple Cylinder):**
* **Label:** "Knowledge Graph"
* **Function:** The data source containing entities and relations.
**4. Query Processing Pipeline (Center):**
* **Query Type Box:** Receives input from the "Query Type" block.
* **Entities and Relations Box:** Receives input from the "Logical Query" block.
* **Neighborhood Retrieval:** An arrow labeled "Neighborhood Retrieval" points from the above two boxes to the "Relevant Subgraphs" block.
* **Relevant Subgraphs (Icon):** Depicts multiple small graph fragments.
* **Prompt Template (Pink Diamond):** Connects to the "Relevant Subgraphs" and feeds into the prompt construction stage.
**5. Prompt Construction & LLM Processing (Right Side):**
* **Context Prompt (Yellow Box):**
* **Text:** "Given the following (h,r,t) triplets: (e₁,r₁,t₁), (e₂,r₂,t₁), (e₂,r₂,t₂), (e₁,r₁,t₂), (e₁,r₁,t₃), (e₂,r₂,t₄), (e₂,r₂,t₅), (e₁,r₁,t₆), ..."
* **Decomposed Question Prompts (Yellow Box):** Contains three dashed-line sub-prompts:
1. "What are the entities connected to **e₁** by relation **r₁**?"
2. "What are the entities connected to **e₂** by relation **r₁**?"
3. "What are the entities in the **intersection** of **P1** and **P2**?"
* **LLM (Green Vertical Box):** The central processing unit. Arrows from the "Context Prompt" and "Decomposed Question Prompts" feed into it. An orange arrow labeled "Add context to question" also points into the LLM.
* **Logically-ordered Answers (Green Box):** Output from the LLM.
* `A1 = P1 = {t₁, t₂, t₃, t₆, ...}`
* `A2 = P2 = {t₁, t₂, t₄, t₅, ...}`
* `A3 = P3 = {t₁, t₂, ...}` (This is the intersection result).
**6. Final Output (Far Right, Orange Box):**
* **Label:** "Final Answer"
* **Content:** "Malala Yousafzai, Rabindranath Tagore, ..."
* **Process:** An arrow labeled "Replace entity ids" points from the "Logically-ordered Answers" (specifically A3) to this final box.
**7. Logical Chain Decomposition (Center-Bottom, Orange Box):**
* **Label:** "Logical Chain Decomposition"
* **Content:** Shows the decomposition of the example "2i" query.
* **Input:** A graph with two entities (e₁, e₂) connected via relations (r₁, r₂) to two predicates (P1, P2), which are then intersected (∧).
* **Output:** Three yellow boxes showing the decomposed sub-queries:
1. e₁ --[r₁]--> P1
2. e₂ --[r₂]--> P2
3. P1 ∧ P2 (Intersection of P1 and P2)
### Detailed Analysis
The diagram details a specific workflow for the example query "Name the Asian Nobel Prize Winners?":
1. **Query Abstraction:** The natural language query is abstracted into a logical graph structure of type "2i" (intersection of two sets).
2. **Decomposition:** The "2i" query is decomposed into two fundamental sub-queries (find Nobel Prize winners; find Asians) and a final intersection operation.
3. **Retrieval:** The system uses the query type and entities/relations to perform "Neighborhood Retrieval" from the Knowledge Graph, obtaining "Relevant Subgraphs."
4. **Prompt Engineering:** A "Prompt Template" is used with the retrieved subgraphs to construct:
* A **Context Prompt** providing example (head, relation, tail) triplets.
* **Decomposed Question Prompts** that ask the LLM to solve each sub-query and the intersection.
5. **LLM Execution:** The LLM processes these prompts. It first answers the sub-queries, producing sets P1 (Nobel Prize Winners) and P2 (Asians). It then computes their intersection (P3).
6. **Answer Generation:** The final set of entity IDs (P3) is mapped back to human-readable names ("Malala Yousafzai, Rabindranath Tagore, ...") to produce the "Final Answer."
### Key Observations
* **Color Coding:** Consistent color use aids understanding: Blue for query types, Orange for logical queries/answers, Purple for the knowledge base, Yellow for prompts, Green for LLM processing.
* **Spatial Flow:** The process flows clearly from left (input) to right (output), with a major decomposition step shown in the lower center.
* **Mathematical Notation:** Uses standard logical symbols (∧ for intersection) and set notation ({t₁, t₂, ...}).
* **Example-Driven:** The entire pipeline is illustrated using a single, concrete example, making the abstract process tangible.
### Interpretation
This diagram demonstrates a **neuro-symbolic** approach to question answering. It combines:
1. **Symbolic AI:** Representing knowledge as a graph, using logical query types (p, 2i, etc.), and performing explicit decomposition and set operations (intersection).
2. **Neural AI (LLM):** Using the LLM's natural language understanding to interpret the decomposed prompts and its reasoning ability to compute the answers from the provided context.
The system's core innovation appears to be the **"Logical Chain Decomposition"** step. Instead of asking the LLM the complex question directly, it breaks the problem into simpler, verifiable sub-tasks (find set A, find set B, find A∩B). This makes the process more transparent, potentially more accurate, and allows the use of retrieved graph data as precise context for the LLM. The "Replace entity ids" step highlights a common challenge in such systems: bridging the gap between internal symbolic representations (IDs like t₁, t₂) and human-readable output. The example answer suggests the knowledge graph contains entities for individuals like Malala Yousafzai and Rabindranath Tagore, linked via relations like "winner" and "citizen."
DECODING INTELLIGENCE...