TECHNICAL ASSET FINGERPRINT
f81082563b1dcaa7fea231de
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: healer-alpha-free VERSION 1
RUNTIME: free/openrouter/healer-alpha
INTEL_VERIFIED
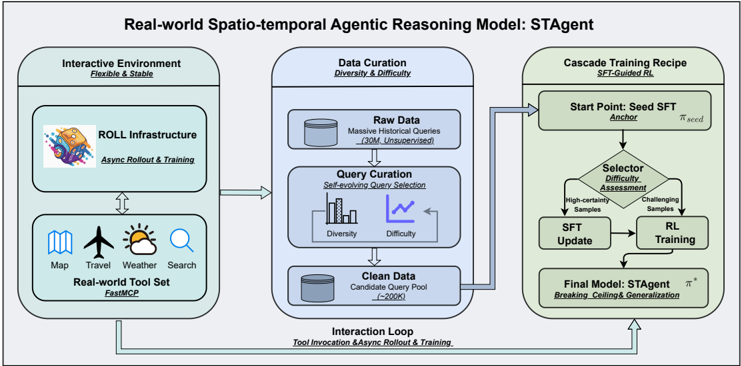
## Diagram: Real-world Spatio-temporal Agentic Reasoning Model: STAgent
### Overview
This image is a technical system architecture diagram illustrating the framework for the "Real-world Spatio-temporal Agentic Reasoning Model: STAgent." The diagram is divided into three primary, interconnected modules arranged horizontally from left to right, with a feedback loop connecting the final module back to the first. The overall flow depicts a pipeline for creating an AI agent capable of reasoning in real-world, spatio-temporal contexts using external tools.
### Components/Axes
The diagram is structured into three main rectangular blocks with rounded corners, each representing a core module of the system. Arrows indicate the flow of data and processes between these modules.
1. **Left Module: Interactive Environment**
* **Title:** Interactive Environment
* **Subtitle:** Flexible & Stable
* **Sub-components:**
* **ROLL Infrastructure:** Contains an icon of a cartoon character (resembling a fox or cat) riding a rocket. Text: "ROLL Infrastructure" and "Async Rollout & Training".
* **Real-world Tool Set:** Contains five icons representing different tools: a map, an airplane, a sun/cloud weather symbol, a magnifying glass (search), and a globe. Text: "Real-world Tool Set" and "Fast&CP".
* **Spatial Grounding:** This module is positioned on the far left of the diagram. An arrow points from this module to the central "Data Curation" module.
2. **Center Module: Data Curation**
* **Title:** Data Curation
* **Subtitle:** Diversity & Difficulty
* **Sub-components:**
* **Raw Data:** Represented by a cylinder (database) icon. Text: "Raw Data" and "Massive Historical Queries (~30M, Unsupervised)".
* **Query Curation:** Text: "Query Curation" and "Self-evaluating Query Selection". Below this are two small charts: a bar chart labeled "Diversity" and a line chart labeled "Difficulty".
* **Clean Data:** Represented by a cylinder icon. Text: "Clean Data" and "Candidate Query Pool (~2000)".
* **Spatial Grounding:** This module is in the center. Arrows flow into it from the left module and out of it to the right module. A large, curved arrow labeled "Interaction Loop" also connects the bottom of this module back to the "Interactive Environment" module.
3. **Right Module: Cascade Training Recipe**
* **Title:** Cascade Training Recipe
* **Subtitle:** SFT-Guided RL
* **Sub-components (flowchart):**
* **Start Point: Seed SFT:** A rectangle. Text: "Start Point: Seed SFT", "Actor", and "π^seed".
* **Selector: Difficulty Assessment:** A diamond (decision) shape. Text: "Selector: Difficulty Assessment". Two arrows exit this diamond: one labeled "High-confidence Samples" pointing to "SFT Update", and another labeled "Challenging Samples" pointing to "RL Training".
* **SFT Update:** A rectangle.
* **RL Training:** A rectangle.
* **Final Model: STAgent:** A rectangle. Text: "Final Model: STAgent", "π*", and "Breaking Ceiling & Generalization".
* **Spatial Grounding:** This module is on the far right. An arrow from the "Clean Data" in the center module points to the "Start Point" of this training recipe. A large, curved arrow labeled "Interaction Loop" originates from the bottom of this module and points back to the "Interactive Environment" on the left.
### Detailed Analysis
The diagram details a closed-loop system for training an AI agent (STAgent).
* **Process Flow:**
1. The **Interactive Environment** provides a stable platform (ROLL Infrastructure) and a set of real-world tools (Map, Travel, Weather, Search) for the agent to interact with.
2. Data for training is processed in the **Data Curation** module. It starts with a massive pool of ~30 million unsupervised historical queries ("Raw Data"). A "Self-evaluating Query Selection" process curates this down to a "Candidate Query Pool" of approximately 2000 high-quality queries ("Clean Data"), optimizing for both "Diversity" and "Difficulty".
3. This curated dataset feeds into the **Cascade Training Recipe**. The training starts with a "Seed SFT" (Supervised Fine-Tuning) model (π^seed). A "Selector" performs "Difficulty Assessment" on data samples. "High-confidence Samples" are used for further "SFT Update", while "Challenging Samples" are used for "RL Training" (Reinforcement Learning). This cascade produces the "Final Model: STAgent" (π*), which is designed for "Breaking Ceiling & Generalization".
4. **Interaction Loop:** A critical feedback loop connects the final trained model back to the interactive environment. The label "Tool Invocation & Async Rollout & Training" indicates that the STAgent's performance in the real-world environment generates new data or experiences, which are fed back into the Data Curation module, enabling continuous learning and improvement.
### Key Observations
* The system emphasizes **data quality over quantity**, reducing 30 million raw queries to just 2000 curated ones.
* The training methodology is a **hybrid approach**, combining Supervised Fine-Tuning (SFT) with Reinforcement Learning (RL), guided by a difficulty-based selector.
* The architecture is explicitly designed as a **continuous learning loop**, not a one-time training pipeline. The "Interaction Loop" is fundamental to the model's ability to generalize and improve.
* The model's goal, "Breaking Ceiling & Generalization," suggests it aims to surpass the limitations of its initial training and perform well on unseen, real-world tasks.
### Interpretation
This diagram outlines a sophisticated framework for building a practical, real-world AI agent. The core innovation lies in the integration of three key ideas: **stable interactive environments**, **intelligent data curation**, and **cascaded, self-improving training**.
The "Interactive Environment" with its "Real-world Tool Set" grounds the agent in practical tasks, moving beyond theoretical benchmarks. The "Data Curation" module acts as a quality filter, ensuring the agent learns from meaningful and challenging examples rather than noisy, raw data. The "Cascade Training Recipe" is particularly insightful; it doesn't just train on static data but uses a selector to dynamically choose the right training method (SFT or RL) based on sample difficulty, mimicking a more human-like learning progression from confident basics to challenging edge cases.
Most importantly, the "Interaction Loop" transforms the system from a static model into a **continuously evolving agent**. By feeding the agent's real-world interactions back into the training pipeline, the system can adapt to new scenarios, correct its own mistakes, and progressively enhance its reasoning capabilities. This reflects a Peircean investigative approach where understanding is refined through ongoing cycles of action, observation, and hypothesis testing. The model, STAgent, is therefore not just a final product but the current state of an agent in a perpetual cycle of learning and improvement.
DECODING INTELLIGENCE...