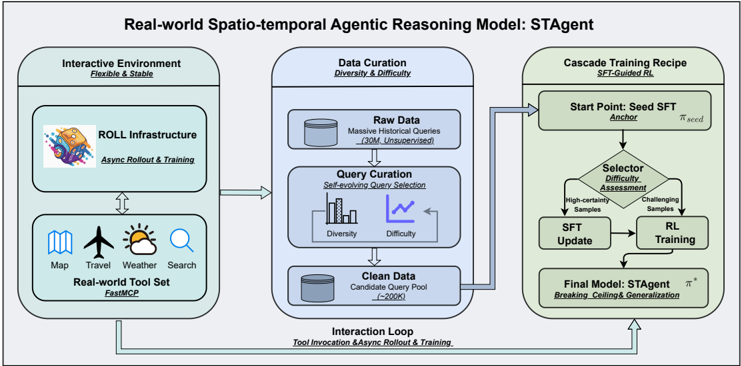
## Diagram: Real-world Spatio-temporal Agentic Reasoning Model: STAgent
### Overview
The diagram illustrates a three-stage pipeline for developing a spatio-temporal reasoning model (STAgent). It integrates real-world data, iterative training, and reinforcement learning (RL) to create an adaptive agent. The system emphasizes handling diverse, challenging data through a feedback loop.
### Components/Axes
1. **Interactive Environment** (Left, green):
- **ROLL Infrastructure**: Labeled with "Async Rollout & Training" and a colorful icon.
- **Real-world Tool Set**: Includes icons for Map, Travel, Weather, Search, and FastMCP (FastMCP labeled below).
- Arrows indicate bidirectional interaction with the Data Curation stage.
2. **Data Curation** (Center, blue):
- **Raw Data**: "Massive Historical Queries (3M+ Unsupervised)" with a database icon.
- **Query Curation**: "Self-evolving Query Selection" with a graph showing Diversity (↑) and Difficulty (↓).
- **Clean Data**: "Candidate Query Pool (C=200K)" with a database icon.
3. **Cascade Training Recipe** (Right, green):
- **Start Point**: "Seed SFT Anchor" with a seed symbol.
- **Selector Difficulty Assessment**: Branches into High-certainty Samples and Challenging Samples.
- **SFT Update** and **RL Training** lead to the Final Model: STAgent (labeled with "Breaking, Celling & Generalization").
4. **Interaction Loop** (Bottom, blue):
- Connects all stages with "Tool Invocation & Async Rollout & Training."
### Detailed Analysis
- **Interactive Environment**: Focuses on real-world data collection via tools (map, weather, etc.) and asynchronous rollout/training.
- **Data Curation**: Processes raw data (3M+ queries) into a curated pool (200K candidates), emphasizing diversity and difficulty trade-offs.
- **Cascade Training**: Uses a difficulty-based selector to split data into high-certainty and challenging samples, iteratively updating the model via SFT and RL.
- **Feedback Loop**: The Interaction Loop ensures continuous refinement through tool use and async rollout.
### Key Observations
- **Data Volume**: Raw data is massive (3M+), but only 200K candidates are retained after curation.
- **Difficulty Handling**: The model explicitly addresses challenging samples via RL training.
- **Modular Design**: Components are isolated (e.g., ROLL Infrastructure, Clean Data) but interconnected via arrows.
### Interpretation
The STAgent model is designed to handle real-world spatio-temporal reasoning by:
1. **Leveraging Real-world Tools**: Integrating diverse data sources (map, weather) to ground the model in practical scenarios.
2. **Iterative Curation**: Using self-evolving queries to refine data quality while balancing diversity and difficulty.
3. **Reinforcement Learning**: Addressing challenging samples through RL to improve generalization and adaptability.
The system’s strength lies in its feedback loop, which ensures continuous learning from real-world interactions. However, the reliance on unsupervised raw data (3M+) raises questions about noise management, though the 200K curated pool suggests robust filtering. The emphasis on "Breaking, Celling & Generalization" implies the model aims to handle edge cases and novel scenarios effectively.