## Scatter Plot: college_computer_science
### Overview
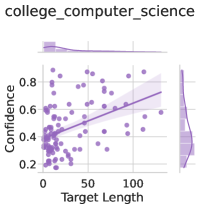
The image is a scatter plot titled "college_computer_science" with a linear regression trend line and shaded confidence interval. It includes marginal histograms on the top and right. The plot visualizes the relationship between "Target Length" (x-axis) and "Confidence" (y-axis), with data points represented as purple dots.
### Components/Axes
- **Title**: "college_computer_science" (top-center).
- **X-axis**: "Target Length" (0 to 100, labeled at bottom).
- **Y-axis**: "Confidence" (0.2 to 0.8, labeled at left).
- **Trend Line**: A purple line with a shaded confidence interval (purple gradient).
- **Marginal Histograms**:
- Top histogram: Distribution of "Target Length" (purple bars).
- Right histogram: Distribution of "Confidence" (purple bars).
### Detailed Analysis
- **Data Points**:
- Purple dots scattered across the plot, with higher density near the trend line.
- Confidence values range from ~0.2 to ~0.8, with most points clustered between 0.4 and 0.6.
- **Trend Line**:
- Slope: Positive (increasing Confidence with Target Length).
- Confidence Interval: Shaded area narrows as Target Length increases, indicating reduced variability at higher lengths.
- **Histograms**:
- **Target Length**: Skewed right, with most values between 0 and 50.
- **Confidence**: Peaks near 0.5–0.6, with a gradual decline toward 0.2 and 0.8.
### Key Observations
1. **Positive Correlation**: Confidence increases with Target Length (e.g., at Target Length = 50, Confidence ≈ 0.5; at Target Length = 100, Confidence ≈ 0.7).
2. **Confidence Interval Narrowing**: The shaded area becomes tighter at higher Target Lengths, suggesting more consistent relationships.
3. **Distribution Patterns**:
- Target Length is more variable (wide spread in the top histogram).
- Confidence is concentrated around the trend line (narrower distribution in the right histogram).
### Interpretation
The data suggests a **positive relationship** between Target Length and Confidence in college computer science contexts. Longer Target Lengths are associated with higher Confidence, and the narrowing confidence interval at higher lengths implies greater reliability in this trend. The histograms reveal that while Target Length varies widely, Confidence is more clustered, particularly around the trend line. This could indicate that longer projects or courses in computer science may correlate with increased student confidence, though variability persists, especially for shorter lengths. The marginal histograms highlight the need to consider both central tendency and distribution when interpreting the relationship.