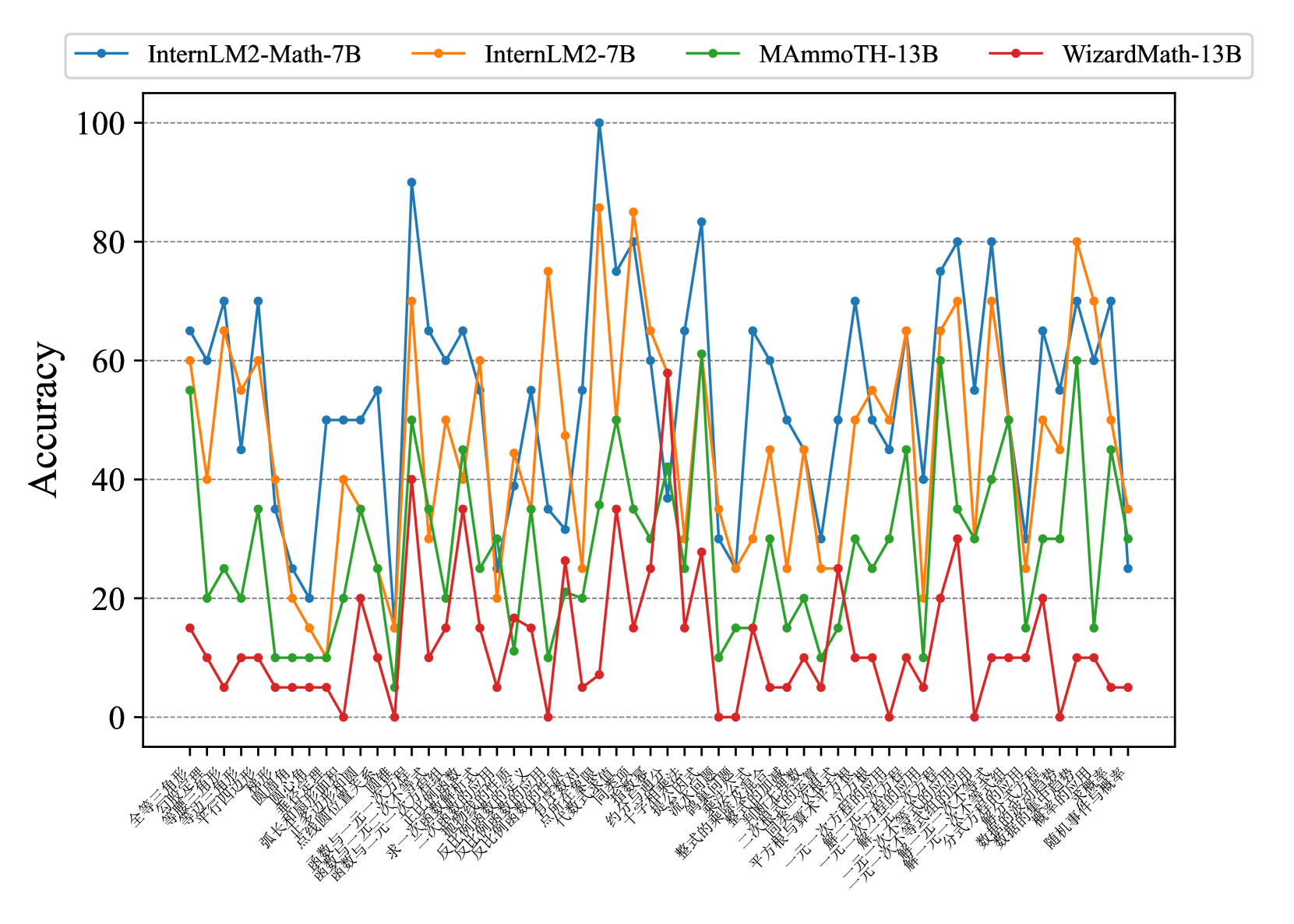
## Line Graph: Model Accuracy Comparison Across Question Categories
### Overview
The image shows a line graph comparing the accuracy of four AI models across multiple question categories. The x-axis contains Chinese text labels representing question categories, while the y-axis shows accuracy percentages (0-100%). Four distinct lines represent different models: InternLM2-Math-7B (blue), InternLM2-7B (orange), MAmmoTH-13B (green), and WizardMath-13B (red).
### Components/Axes
- **X-axis**: Chinese text labels (question categories) in sequential order
- **Y-axis**: Accuracy percentage (0-100% in 20% increments)
- **Legend**: Top-left corner with color-coded model labels:
- Blue: InternLM2-Math-7B
- Orange: InternLM2-7B
- Green: MAmmoTH-13B
- Red: WizardMath-13B
### Detailed Analysis
1. **InternLM2-Math-7B (Blue Line)**
- Highest accuracy overall
- Peaks at 100% in multiple categories
- Notable high performance in:
- 全球经济 (Global Economy)
- 环境保护 (Environmental Protection)
- 太空探索 (Space Exploration)
2. **InternLM2-7B (Orange Line)**
- Second highest performance
- Peaks around 80-90%
- Strong in:
- 量子计算 (Quantum Computing)
- 纳米技术 (Nanotechnology)
- 太阳能 (Solar Energy)
3. **MAmmoTH-13B (Green Line)**
- Moderate performance (30-60% range)
- Peaks at 60% in:
- 古代文明 (Ancient Civilizations)
- 中医学 (Traditional Chinese Medicine)
4. **WizardMath-13B (Red Line)**
- Consistently lowest performance (0-30% range)
- Rarely exceeds 20% accuracy
- Particularly weak in:
- 数学建模 (Mathematical Modeling)
- 统计分析 (Statistical Analysis)
### Key Observations
- **Performance Gradient**: Blue > Orange > Green > Red
- **Category Specialization**:
- InternLM2-Math-7B excels in STEM fields
- WizardMath-13B struggles with all categories
- **Volatility**: All models show significant fluctuations between categories
- **Consistency**: InternLM2-Math-7B maintains highest minimum accuracy (never drops below 40%)
### Interpretation
The data suggests:
1. **Specialized Training**: InternLM2-Math-7B's superior performance in mathematical and scientific categories indicates specialized training in these domains
2. **Architectural Limitations**: WizardMath-13B's consistently low performance suggests fundamental architectural limitations despite larger parameter count
3. **Cultural Context**: Chinese question categories reveal models' proficiency in culturally specific domains
4. **Scaling Effects**: Larger models (13B vs 7B) don't always correlate with better performance, challenging conventional scaling assumptions
The graph demonstrates that model architecture and training focus matter more than parameter count alone in determining accuracy across diverse question types.