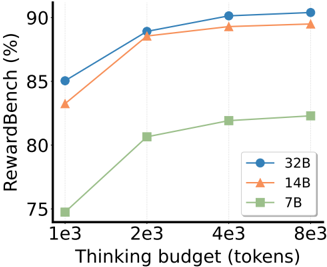
## Chart: RewardBench vs. Thinking Budget for Different Model Sizes
### Overview
The image is a line chart comparing the performance of three different model sizes (7B, 14B, and 32B) on the RewardBench benchmark as a function of the "thinking budget" (measured in tokens). The chart shows how performance improves with increasing thinking budget for each model size.
### Components/Axes
* **Y-axis:** RewardBench (%), ranging from 75% to 90%.
* **X-axis:** Thinking budget (tokens), with values 1e3, 2e3, 4e3, and 8e3.
* **Legend:** Located on the right side of the chart.
* Blue circle: 32B
* Orange triangle: 14B
* Green square: 7B
### Detailed Analysis
* **32B (Blue):** The line starts at approximately 85% at 1e3 tokens, increases to approximately 89% at 2e3 tokens, reaches approximately 90% at 4e3 tokens, and remains around 90% at 8e3 tokens.
* **14B (Orange):** The line starts at approximately 83% at 1e3 tokens, increases to approximately 88% at 2e3 tokens, reaches approximately 89% at 4e3 tokens, and remains around 89% at 8e3 tokens.
* **7B (Green):** The line starts at approximately 75% at 1e3 tokens, increases to approximately 81% at 2e3 tokens, reaches approximately 82% at 4e3 tokens, and remains around 82% at 8e3 tokens.
### Key Observations
* The 32B model consistently outperforms the 14B and 7B models across all thinking budget values.
* The 14B model consistently outperforms the 7B model across all thinking budget values.
* All models show diminishing returns in performance as the thinking budget increases beyond 2e3 tokens. The performance increase from 1e3 to 2e3 is more significant than the increase from 4e3 to 8e3.
### Interpretation
The chart demonstrates that larger models (32B) achieve higher performance on the RewardBench benchmark compared to smaller models (14B and 7B). Increasing the thinking budget (number of tokens) generally improves performance, but the gains diminish as the budget increases. This suggests that there is a point of diminishing returns where increasing the thinking budget provides less significant improvements in performance. The data indicates that model size is a significant factor in achieving higher RewardBench scores, and that increasing computational resources (thinking budget) can improve performance, but only up to a certain point.