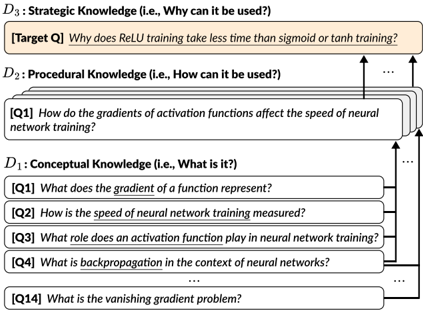
## Diagram: Hierarchical Knowledge Structure for Neural Network Training
### Overview
The diagram illustrates a three-tiered knowledge framework for understanding neural network training, organized vertically from foundational concepts to strategic applications. Arrows indicate a top-down flow of knowledge integration.
### Components/Axes
- **D1: Conceptual Knowledge** (Bottom tier)
- Title: "What is it?"
- Sub-components:
- Q1: What does the gradient of a function represent?
- Q2: How is the speed of neural network training measured?
- Q3: What role does an activation function play in neural network training?
- Q4: What is backpropagation in the context of neural networks?
- Q14: What is the vanishing gradient problem?
- **D2: Procedural Knowledge** (Middle tier)
- Title: "How can it be used?"
- Sub-component:
- Q1: How do the gradients of activation functions affect the speed of neural network training?
- **D3: Strategic Knowledge** (Top tier)
- Title: "Why can it be used?"
- Sub-component:
- Target Q: Why does ReLU training take less time than sigmoid or tanh training?
### Detailed Analysis
- **D1 Questions**: Focus on foundational concepts (gradients, training speed metrics, activation functions, backpropagation, and optimization challenges like vanishing gradients).
- **D2 Question**: Bridges conceptual understanding to practical application by linking activation function gradients to training efficiency.
- **D3 Target Q**: Synthesizes knowledge to explain the practical advantage of ReLU over traditional activation functions.
### Key Observations
1. The hierarchy progresses from basic definitions (D1) to applied understanding (D2) and finally to strategic reasoning (D3).
2. The Target Q in D3 directly addresses a real-world optimization concern (training speed comparison).
3. Arrows suggest that answering D1 questions enables mastery of D2, which in turn informs D3.
### Interpretation
This framework demonstrates a pedagogical approach to teaching neural network training:
1. **Conceptual Foundation**: Mastery of gradients, backpropagation, and activation functions (D1) is prerequisite for understanding training mechanics.
2. **Procedural Application**: Knowing how gradients influence training speed (D2) requires first understanding what gradients represent (D1 Q1).
3. **Strategic Insight**: The Target Q in D3 exemplifies how this knowledge hierarchy enables engineers to optimize models by selecting activation functions based on computational efficiency.
The diagram emphasizes that effective neural network training requires not just memorizing procedures (e.g., "use ReLU"), but understanding the underlying mathematical principles (gradients, backpropagation) and their practical implications (training speed tradeoffs).