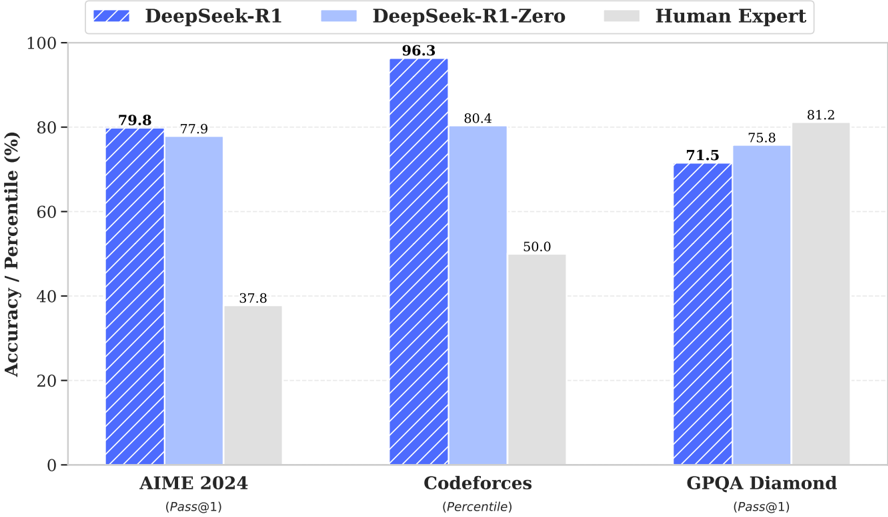
## Bar Chart: DeepSeek-R1 vs. DeepSeek-R1-Zero vs. Human Expert Performance
### Overview
The image is a bar chart comparing the performance of DeepSeek-R1, DeepSeek-R1-Zero, and Human Experts on three different tasks: AIME 2024, Codeforces, and GPQA Diamond. The chart displays accuracy/percentile scores for each entity on each task.
### Components/Axes
* **Title:** None explicitly given in the image.
* **X-axis:** Categorical axis with three categories: "AIME 2024 (Pass@1)", "Codeforces (Percentile)", and "GPQA Diamond (Pass@1)".
* **Y-axis:** Numerical axis labeled "Accuracy / Percentile (%)", ranging from 0 to 100.
* **Legend:** Located at the top of the chart.
* Blue with diagonal lines: "DeepSeek-R1"
* Light Blue: "DeepSeek-R1-Zero"
* Light Gray: "Human Expert"
### Detailed Analysis
The chart presents three sets of bars for each task, representing the performance of DeepSeek-R1, DeepSeek-R1-Zero, and Human Experts.
* **AIME 2024 (Pass@1):**
* DeepSeek-R1 (Blue with diagonal lines): 79.8%
* DeepSeek-R1-Zero (Light Blue): 77.9%
* Human Expert (Light Gray): 37.8%
* **Codeforces (Percentile):**
* DeepSeek-R1 (Blue with diagonal lines): 96.3%
* DeepSeek-R1-Zero (Light Blue): 80.4%
* Human Expert (Light Gray): 50.0%
* **GPQA Diamond (Pass@1):**
* DeepSeek-R1 (Blue with diagonal lines): 71.5%
* DeepSeek-R1-Zero (Light Blue): 75.8%
* Human Expert (Light Gray): 81.2%
### Key Observations
* DeepSeek-R1 performs best on Codeforces, achieving a score of 96.3%.
* Human Experts perform best on GPQA Diamond, achieving a score of 81.2%.
* DeepSeek-R1 significantly outperforms Human Experts on AIME 2024 and Codeforces.
* On GPQA Diamond, Human Experts outperform both DeepSeek-R1 and DeepSeek-R1-Zero.
### Interpretation
The bar chart illustrates the comparative performance of two AI models (DeepSeek-R1 and DeepSeek-R1-Zero) against human experts across three distinct tasks. The results suggest that AI models, particularly DeepSeek-R1, excel in certain areas like Codeforces and AIME 2024, surpassing human capabilities. However, in the GPQA Diamond task, human experts demonstrate superior performance, indicating that certain problem-solving domains still favor human expertise. The difference between DeepSeek-R1 and DeepSeek-R1-Zero highlights the impact of specific training methodologies or model architectures on task-specific performance. The "Pass@1" notation for AIME 2024 and GPQA Diamond likely refers to the accuracy of achieving the correct answer on the first attempt. The "Percentile" notation for Codeforces indicates the model's performance relative to other participants.