\n
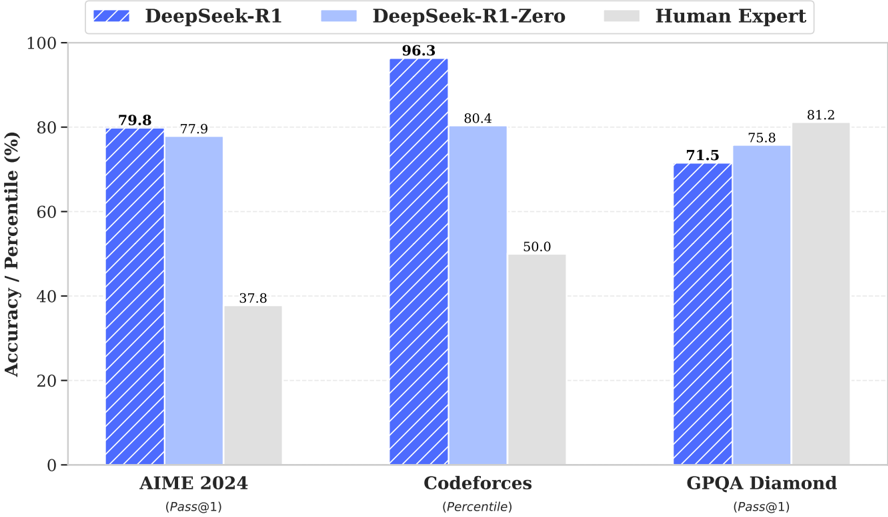
## Bar Chart: Performance Comparison of AI Models and Human Experts
### Overview
This bar chart compares the performance of three different models – DeepSeek-R1, DeepSeek-R1-Zero, and a Human Expert – on three different coding challenges: AIME 2024, Codeforces, and GPQA Diamond. The performance is measured in terms of Accuracy/Percentile (%).
### Components/Axes
* **X-axis:** Represents the coding challenges: AIME 2024, Codeforces, and GPQA Diamond. Below each challenge name is a metric in parentheses: (Pass@1) for AIME 2024 and GPQA Diamond, and (Percentile) for Codeforces.
* **Y-axis:** Represents Accuracy/Percentile (%), ranging from 0 to 100.
* **Legend:** Located at the top-left corner, it identifies the three data series using color-coding:
* DeepSeek-R1 (Dark Blue, hatched pattern)
* DeepSeek-R1-Zero (Light Blue)
* Human Expert (Light Gray)
### Detailed Analysis
The chart consists of three groups of bars, one for each coding challenge. Within each group, there are three bars representing the performance of each model.
**AIME 2024:**
* DeepSeek-R1: Approximately 79.8% accuracy.
* DeepSeek-R1-Zero: Approximately 77.9% accuracy.
* Human Expert: Approximately 37.8% accuracy.
**Codeforces:**
* DeepSeek-R1: Approximately 96.3% accuracy. This is the highest value in the entire chart.
* DeepSeek-R1-Zero: Approximately 80.4% accuracy.
* Human Expert: Approximately 50.0% accuracy.
**GPQA Diamond:**
* DeepSeek-R1: Approximately 71.5% accuracy.
* DeepSeek-R1-Zero: Approximately 75.8% accuracy.
* Human Expert: Approximately 81.2% accuracy.
### Key Observations
* DeepSeek-R1 consistently performs well across all three challenges, achieving the highest score on Codeforces.
* DeepSeek-R1-Zero generally performs slightly lower than DeepSeek-R1, but still outperforms the Human Expert on Codeforces and AIME 2024.
* The Human Expert performs significantly lower than both AI models on AIME 2024 and Codeforces, but achieves the highest score on GPQA Diamond.
* The performance gap between the AI models and the Human Expert is most pronounced on Codeforces.
### Interpretation
The data suggests that the DeepSeek models, particularly DeepSeek-R1, demonstrate superior performance on these coding challenges compared to a human expert, especially on Codeforces. This could indicate that these models are better at solving problems that require a high degree of algorithmic thinking and code generation. The Human Expert's higher score on GPQA Diamond might suggest that this challenge requires a different skillset, such as problem understanding or creative problem-solving, where human intuition still holds an advantage. The difference in performance across the challenges could also be due to the nature of the problems themselves – some challenges might be more amenable to automated solutions than others. The metric used for each challenge (Pass@1 vs. Percentile) may also contribute to the observed differences. The Pass@1 metric indicates whether the model's first attempt is correct, while Percentile indicates the model's ranking relative to other participants.