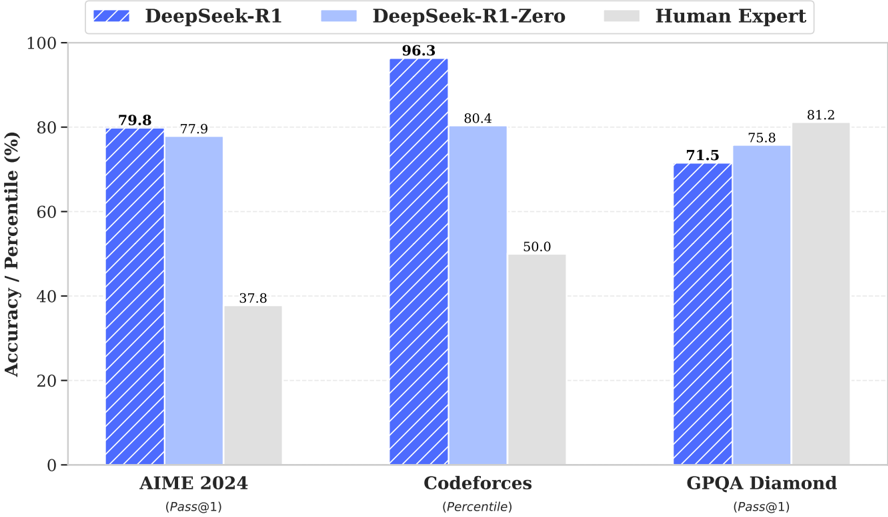
## Grouped Bar Chart: Model Performance Comparison Across Benchmarks
### Overview
This image is a grouped bar chart comparing the performance of three entities—DeepSeek-R1, DeepSeek-R1-Zero, and Human Expert—across three distinct benchmarks: AIME 2024, Codeforces, and GPQA Diamond. The chart displays accuracy or percentile scores as percentages.
### Components/Axes
* **Y-Axis:** Labeled "Accuracy / Percentile (%)". The scale runs from 0 to 100 in increments of 20.
* **X-Axis:** Lists three benchmark categories:
1. **AIME 2024** (with sub-label "(Pass@1)")
2. **Codeforces** (with sub-label "(Percentile)")
3. **GPQA Diamond** (with sub-label "(Pass@1)")
* **Legend:** Positioned at the top center of the chart. It defines three data series:
* **DeepSeek-R1:** Represented by a blue bar with diagonal white stripes.
* **DeepSeek-R1-Zero:** Represented by a solid, light blue bar.
* **Human Expert:** Represented by a solid, light gray bar.
* **Data Labels:** Numerical values are printed directly above each bar for precise reading.
### Detailed Analysis
The analysis is segmented by benchmark category, following the left-to-right order on the x-axis.
**1. AIME 2024 (Pass@1)**
* **Visual Trend:** The two AI models perform similarly and significantly outperform the Human Expert baseline.
* **Data Points:**
* DeepSeek-R1 (striped blue): **79.8%**
* DeepSeek-R1-Zero (light blue): **77.9%**
* Human Expert (gray): **37.8%**
**2. Codeforces (Percentile)**
* **Visual Trend:** DeepSeek-R1 shows a dominant performance, achieving the highest score on the entire chart. DeepSeek-R1-Zero also performs strongly, while the Human Expert score is notably lower.
* **Data Points:**
* DeepSeek-R1 (striped blue): **96.3%**
* DeepSeek-R1-Zero (light blue): **80.4%**
* Human Expert (gray): **50.0%**
**3. GPQA Diamond (Pass@1)**
* **Visual Trend:** This benchmark shows a different pattern. The Human Expert achieves the highest score, followed by DeepSeek-R1-Zero, with DeepSeek-R1 scoring the lowest of the three.
* **Data Points:**
* DeepSeek-R1 (striped blue): **71.5%**
* DeepSeek-R1-Zero (light blue): **75.8%**
* Human Expert (gray): **81.2%**
### Key Observations
1. **Performance Variability:** DeepSeek-R1's performance is highly variable across tasks, ranging from a chart-leading 96.3% on Codeforces to its lowest score of 71.5% on GPQA Diamond.
2. **Human Expert Benchmark:** The Human Expert baseline is not static; it varies dramatically by domain, from a low of 37.8% on AIME 2024 to a high of 81.2% on GPQA Diamond.
3. **Model Comparison:** DeepSeek-R1-Zero generally performs slightly worse than DeepSeek-R1 on AIME and Codeforces but slightly better on GPQA Diamond.
4. **Task-Specific Strengths:** The data suggests the AI models (particularly DeepSeek-R1) have a pronounced strength in the mathematical (AIME) and competitive programming (Codeforces) domains compared to the human expert baseline provided. Their advantage diminishes or reverses on the GPQA Diamond benchmark.
### Interpretation
This chart illustrates the concept of **task-dependent performance** in AI systems. The data suggests that while the DeepSeek-R1 models can achieve superhuman-level performance on specific, well-defined technical benchmarks like competitive programming (Codeforces, 96.3rd percentile) and math problems (AIME, ~80% pass@1), their superiority is not universal. On the GPQA Diamond benchmark, which likely tests a different set of reasoning or knowledge skills, the Human Expert baseline is superior.
The significant variance in the "Human Expert" score (37.8% to 81.2%) is a critical piece of context. It indicates that the benchmarks themselves measure very different skills, and "human-level performance" is not a single point but a spectrum across domains. The chart effectively argues that evaluating AI requires multiple, diverse benchmarks, as strength in one area (e.g., coding) does not guarantee strength in another (e.g., the domain tested by GPQA Diamond). The near-parity between DeepSeek-R1 and DeepSeek-R1-Zero on two of three tasks suggests the core capabilities are robust, with minor variations possibly due to training differences.