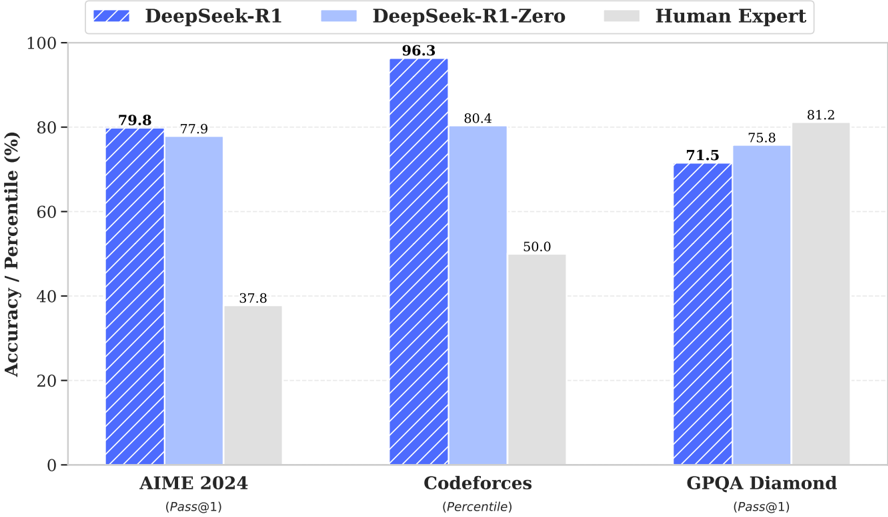
## Bar Chart: Model Performance Comparison Across Benchmarks
### Overview
The chart compares the performance of three models—**DeepSeek-R1**, **DeepSeek-R1-Zero**, and **Human Expert**—across three benchmarks: **AIME 2024**, **Codeforces**, and **GPQA Diamond**. Performance is measured as **Accuracy/Percentile (%)**, with values displayed on top of each bar. The chart uses distinct colors and patterns to differentiate the models.
---
### Components/Axes
- **X-Axis (Categories)**:
- AIME 2024 (Pass@1)
- Codeforces (Percentile)
- GPQA Diamond (Pass@1)
- **Y-Axis (Values)**:
- Accuracy/Percentile (%) ranging from 0 to 100.
- **Legend**:
- **DeepSeek-R1**: Blue with diagonal white stripes.
- **DeepSeek-R1-Zero**: Light blue.
- **Human Expert**: Gray.
- **Bar Placement**:
- Each benchmark has three grouped bars (one per model).
- Legend is positioned at the **top-left** of the chart.
---
### Detailed Analysis
1. **AIME 2024**:
- **DeepSeek-R1**: 79.8% (blue striped bar).
- **DeepSeek-R1-Zero**: 77.9% (light blue bar).
- **Human Expert**: 37.8% (gray bar).
2. **Codeforces**:
- **DeepSeek-R1**: 96.3% (blue striped bar).
- **DeepSeek-R1-Zero**: 80.4% (light blue bar).
- **Human Expert**: 50.0% (gray bar).
3. **GPQA Diamond**:
- **DeepSeek-R1**: 71.5% (blue striped bar).
- **DeepSeek-R1-Zero**: 75.8% (light blue bar).
- **Human Expert**: 81.2% (gray bar).
---
### Key Observations
- **DeepSeek-R1** consistently outperforms **DeepSeek-R1-Zero** in **AIME 2024** and **Codeforces**, but underperforms in **GPQA Diamond**.
- **Human Expert** scores are significantly lower than both models in **AIME 2024** and **Codeforces** but surpass both in **GPQA Diamond**.
- **Codeforces** shows the largest gap between models, with **DeepSeek-R1** achieving near-perfect performance (96.3%).
---
### Interpretation
- **Model Strengths**:
- **DeepSeek-R1** excels in **Codeforces**, suggesting strong algorithmic problem-solving capabilities.
- **Human Expert** performs best in **GPQA Diamond**, indicating that human reasoning may be more effective for complex, nuanced tasks in this domain.
- **Model Limitations**:
- **DeepSeek-R1-Zero** lags behind **DeepSeek-R1** in most benchmarks, highlighting the value of iterative training (R1 vs. R1-Zero).
- **Human Expert** underperforms in **AIME 2024** and **Codeforces**, possibly due to the benchmarks' alignment with model training data or automated evaluation criteria.
- **Trends**:
- The disparity between models in **GPQA Diamond** suggests that human expertise retains an edge in tasks requiring deeper contextual understanding or creativity.
- **DeepSeek-R1**'s dominance in **Codeforces** underscores its specialization in competitive programming and structured problem-solving.
This analysis highlights the complementary strengths of AI models and human experts, with each excelling in different domains.