\n
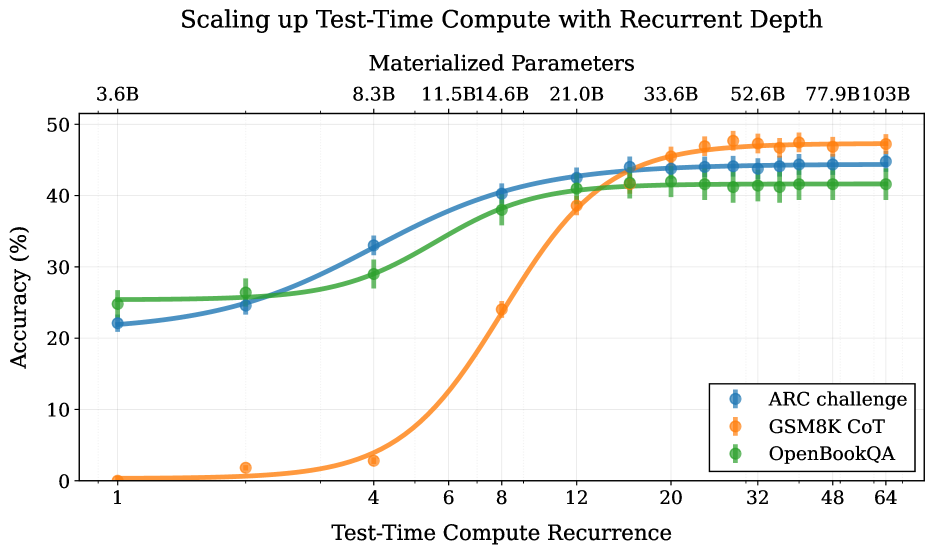
## Chart: Scaling up Test-Time Compute with Recurrent Depth
### Overview
This chart illustrates the relationship between Test-Time Compute Recurrence and Accuracy (%) for three different datasets: ARC challenge, GSM8K CoT, and OpenBookQA, across varying Materialized Parameters. The chart demonstrates how increasing the depth of computation during test time impacts the accuracy of each dataset, with performance scaling alongside the number of materialized parameters.
### Components/Axes
* **Title:** Scaling up Test-Time Compute with Recurrent Depth
* **X-axis:** Test-Time Compute Recurrence (Scale: 1, 4, 6, 8, 12, 20, 32, 48, 64)
* **Y-axis:** Accuracy (%) (Scale: 0 to 50)
* **Materialized Parameters (Top Axis):** 3.6B, 8.3B, 11.5B, 14.6B, 21.0B, 33.6B, 52.6B, 77.9B, 103B
* **Legend:**
* ARC challenge (Blue)
* GSM8K CoT (Orange)
* OpenBookQA (Green)
### Detailed Analysis
The chart displays three lines representing the accuracy of each dataset as Test-Time Compute Recurrence increases. The Materialized Parameters are displayed along the top of the chart, indicating the model size used for each data point.
**ARC challenge (Blue):**
* The line starts at approximately 22% accuracy at a recurrence of 1.
* It gradually increases to around 28% at a recurrence of 4.
* A steeper increase is observed between recurrences 4 and 8, reaching approximately 38%.
* The line plateaus around 42-45% accuracy from a recurrence of 12 onwards.
* Approximate data points: (1, 22%), (4, 28%), (6, 34%), (8, 38%), (12, 41%), (20, 43%), (32, 44%), (48, 44%), (64, 45%)
**GSM8K CoT (Orange):**
* The line begins at approximately 1% accuracy at a recurrence of 1.
* It remains very low until a recurrence of 6, where it starts to increase rapidly.
* Between recurrences 6 and 12, the accuracy jumps from roughly 2% to around 42%.
* The line then plateaus, fluctuating between 42% and 46% accuracy from a recurrence of 12 onwards.
* Approximate data points: (1, 1%), (4, 1%), (6, 2%), (8, 15%), (12, 42%), (20, 45%), (32, 45%), (48, 45%), (64, 46%)
**OpenBookQA (Green):**
* The line starts at approximately 24% accuracy at a recurrence of 1.
* It shows a moderate increase to around 30% at a recurrence of 4.
* The line continues to increase, reaching approximately 36% at a recurrence of 8.
* It plateaus around 40-42% accuracy from a recurrence of 12 onwards.
* Approximate data points: (1, 24%), (4, 30%), (6, 33%), (8, 36%), (12, 39%), (20, 41%), (32, 41%), (48, 41%), (64, 42%)
### Key Observations
* GSM8K CoT shows the most dramatic improvement in accuracy with increasing recurrence, starting from a very low baseline.
* ARC challenge and OpenBookQA exhibit more gradual improvements and reach higher plateaus.
* All three datasets show diminishing returns in accuracy beyond a recurrence of 12.
* Higher Materialized Parameters generally correlate with higher accuracy, particularly for GSM8K CoT.
* The ARC challenge consistently performs better than GSM8K CoT at lower recurrence values, but GSM8K CoT catches up and surpasses it at higher recurrence values.
### Interpretation
The data suggests that increasing the depth of computation during test time (Test-Time Compute Recurrence) can significantly improve the accuracy of language models, especially for datasets like GSM8K CoT that benefit from more complex reasoning. The plateauing effect observed at higher recurrence values indicates that there is a limit to the benefits of increasing computation depth, and that other factors (such as model size or training data) may become more important. The varying performance of the three datasets suggests that the optimal level of test-time computation depth may depend on the specific characteristics of the task. The strong correlation between Materialized Parameters and accuracy highlights the importance of model size in achieving high performance. The fact that GSM8K CoT starts with very low accuracy and then rapidly improves suggests that it is a particularly challenging task that requires significant computational resources to solve effectively. The diminishing returns observed at higher recurrence values suggest that there is a trade-off between computational cost and accuracy gains.