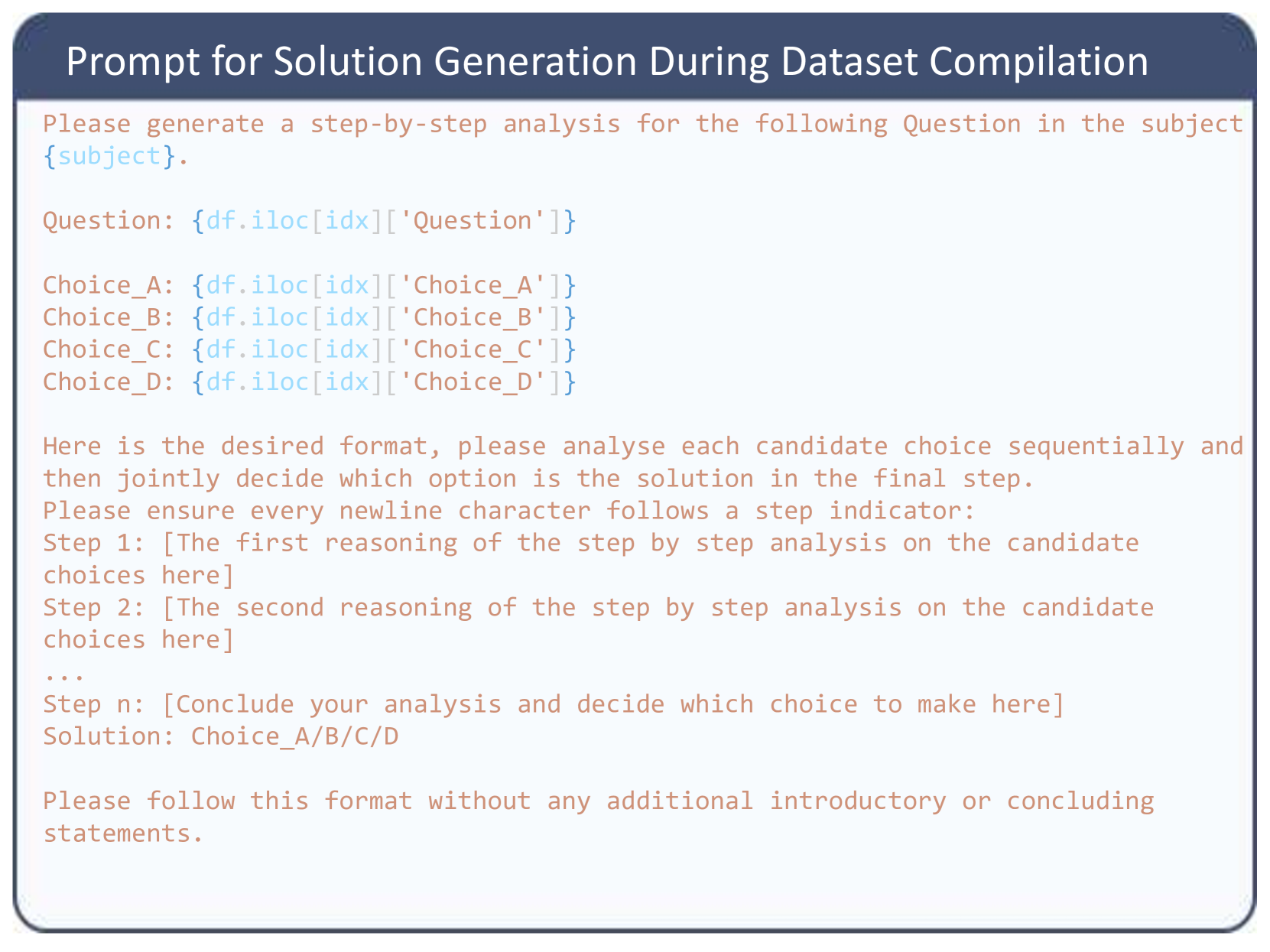
## Text Block / Prompt Template: Prompt for Solution Generation During Dataset Compilation
### Overview
This image displays a structured text block representing a prompt template used in artificial intelligence and machine learning. Specifically, it is an instruction set designed to be fed into a Large Language Model (LLM) to automatically generate step-by-step reasoning (Chain-of-Thought) for multiple-choice questions. The image contains no charts, graphs, or data tables; it consists entirely of formatted text within a graphical user interface (GUI) style container.
### Components/Layout
The image is divided into two primary spatial regions:
1. **Header (Top):** A dark blue rectangular banner spanning the width of the image containing white text.
2. **Main Body (Center to Bottom):** A larger rectangular area with a white/very light gray background and a rounded border. The text inside uses a monospaced or typewriter-style font and is color-coded:
* **Salmon/Reddish-Brown Text:** Represents static instructions and formatting templates that remain constant.
* **Light Blue Text:** Represents dynamic variables or code snippets that will be injected into the prompt programmatically.
### Content Details (Transcription)
**Header Text:**
Prompt for Solution Generation During Dataset Compilation
**Main Body Text:**
*(Note: Text in `[brackets]` indicates the light blue variable text in the original image; the rest is the salmon-colored static text).*
Please generate a step-by-step analysis for the following Question in the subject `[{subject}]`.
Question: `[{df.iloc[idx]['Question']}]`
Choice_A: `[{df.iloc[idx]['Choice_A']}]`
Choice_B: `[{df.iloc[idx]['Choice_B']}]`
Choice_C: `[{df.iloc[idx]['Choice_C']}]`
Choice_D: `[{df.iloc[idx]['Choice_D']}]`
Here is the desired format, please analyse each candidate choice sequentially and then jointly decide which option is the solution in the final step.
Please ensure every newline character follows a step indicator:
Step 1: [The first reasoning of the step by step analysis on the candidate choices here]
Step 2: [The second reasoning of the step by step analysis on the candidate choices here]
...
Step n: [Conclude your analysis and decide which choice to make here]
Solution: Choice_A/B/C/D
Please follow this format without any additional introductory or concluding statements.
### Key Observations
* **Programming Syntax:** The light blue variables utilize standard Python syntax, specifically the Pandas library. `df.iloc[idx]['ColumnName']` indicates that a script is iterating through a DataFrame (`df`) using an index (`idx`) to extract specific strings for the 'Question' and the four choices ('Choice_A' through 'Choice_D').
* **Strict Formatting Constraints:** The prompt explicitly forbids "additional introductory or concluding statements" (often referred to as "chatty" behavior in LLMs, like "Sure, I can help with that!"). It also strictly mandates how newline characters should be used.
* **Chain-of-Thought Elicitation:** The prompt forces the model to generate "Step 1", "Step 2", etc., before arriving at the final "Solution".
### Interpretation
This image provides a behind-the-scenes look at how synthetic datasets are created for training or fine-tuning AI models.
**What the data demonstrates:**
The creators of this dataset already have a database (likely a CSV or Parquet file loaded as a Pandas DataFrame) containing subjects, questions, and multiple-choice options. However, they lack the *reasoning* (the "why") behind the correct answers. They are using a capable LLM (like GPT-4 or Claude) to act as a "teacher" to generate this missing reasoning.
**How the elements relate:**
A Python script will loop through the database. For row 1, it will replace `{subject}`, `{df.iloc[idx]['Question']}`, etc., with the actual text from the database. It sends this completed text to an LLM. The LLM reads the strict formatting rules and outputs a highly structured, step-by-step explanation ending with the correct choice. The script then saves this output back into the database.
**Why it matters (Peircean investigative reading):**
The extreme strictness of the formatting instructions ("ensure every newline character follows a step indicator", "without any additional introductory... statements") reveals a common pain point in AI engineering: parsing LLM outputs. If the LLM generates conversational filler, the automated script trying to extract the reasoning and the final answer will break. By forcing a rigid structure, the engineers ensure they can use simple Regular Expressions (Regex) or string splitting to separate the reasoning steps from the final answer, thereby creating a clean, high-quality dataset that can be used to train smaller, less capable models to reason better.