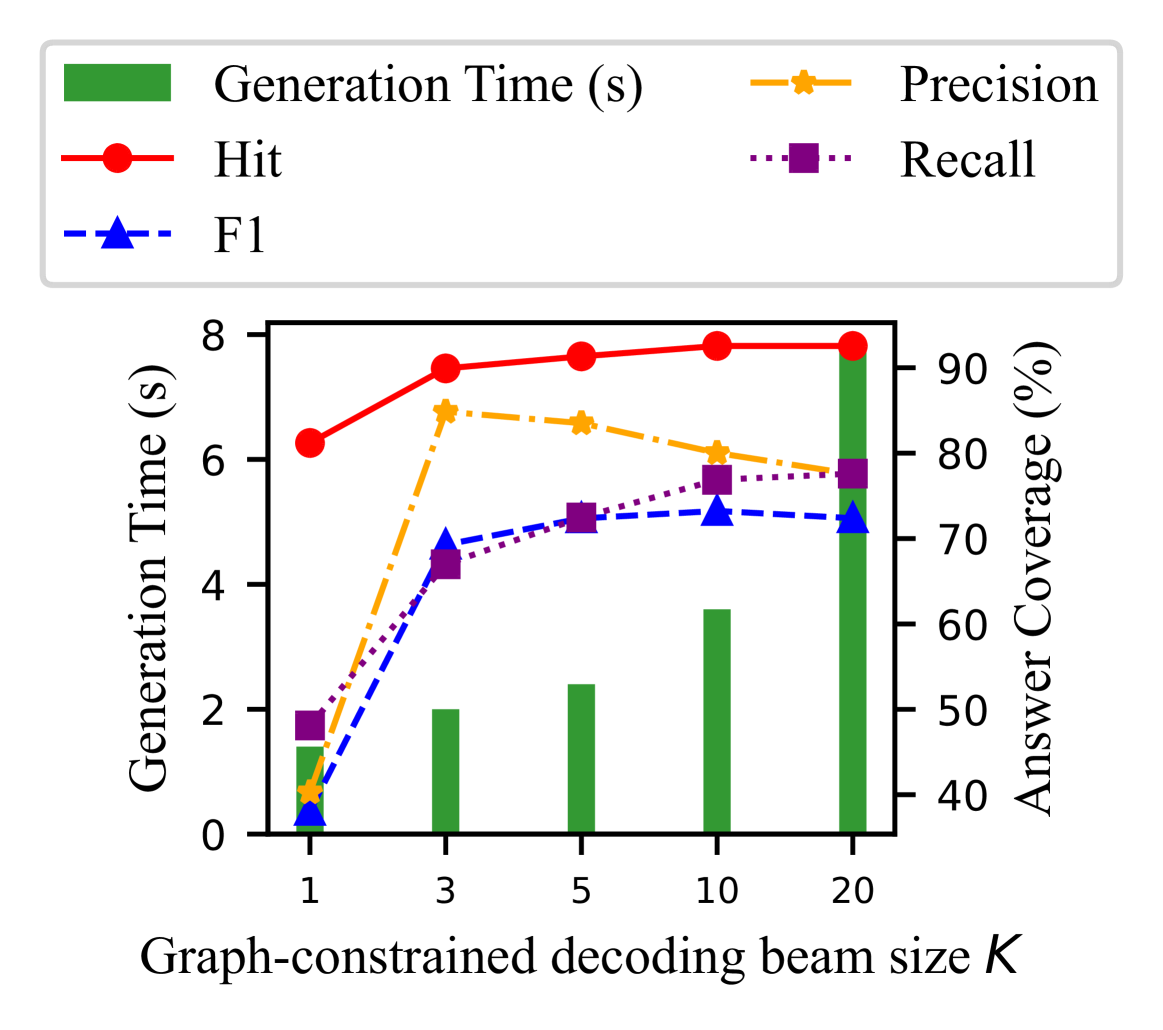
## Chart: Graph-constrained Decoding Beam Size vs. Performance Metrics
### Overview
The image is a chart displaying the relationship between the graph-constrained decoding beam size (K) and several performance metrics: Generation Time, Hit, Precision, Recall, and F1. The x-axis represents the beam size K, while the left y-axis represents Generation Time in seconds, and the right y-axis represents Answer Coverage in percentage.
### Components/Axes
* **X-axis:** Graph-constrained decoding beam size K, with values 1, 3, 5, 10, and 20.
* **Left Y-axis:** Generation Time (s), ranging from 0 to 8 seconds, with increments of 2 seconds.
* **Right Y-axis:** Answer Coverage (%), ranging from 40 to 90 percent, with increments of 10 percent.
* **Legend (top-left):**
* Green: Generation Time (s) - represented as vertical bars.
* Red: Hit - represented as a solid line with circle markers.
* Blue: F1 - represented as a dashed line with triangle markers.
* **Legend (top-right):**
* Orange: Precision - represented as a dash-dot line with star markers.
* Purple: Recall - represented as a dotted line with square markers.
### Detailed Analysis
* **Generation Time (s) - Green Bars:**
* K=1: Approximately 1 second.
* K=3: Approximately 2 seconds.
* K=5: Approximately 2.5 seconds.
* K=10: Approximately 3.5 seconds.
* K=20: Approximately 8 seconds.
* Trend: Generation time increases with increasing beam size K.
* **Hit - Red Line:**
* K=1: Approximately 63%.
* K=3: Approximately 75%.
* K=5: Approximately 77%.
* K=10: Approximately 78%.
* K=20: Approximately 79%.
* Trend: Hit increases sharply from K=1 to K=3, then plateaus.
* **Precision - Orange Line:**
* K=1: Approximately 50%.
* K=3: Approximately 68%.
* K=5: Approximately 65%.
* K=10: Approximately 65%.
* K=20: Approximately 62%.
* Trend: Precision increases sharply from K=1 to K=3, then decreases slightly.
* **Recall - Purple Line:**
* K=1: Approximately 43%.
* K=3: Approximately 68%.
* K=5: Approximately 73%.
* K=10: Approximately 75%.
* K=20: Approximately 78%.
* Trend: Recall increases with increasing beam size K, but the rate of increase slows down.
* **F1 - Blue Line:**
* K=1: Approximately 41%.
* K=3: Approximately 69%.
* K=5: Approximately 71%.
* K=10: Approximately 72%.
* K=20: Approximately 73%.
* Trend: F1 increases with increasing beam size K, but the rate of increase slows down.
### Key Observations
* Generation Time increases linearly with the beam size K.
* Hit, Precision, Recall, and F1 all increase significantly from K=1 to K=3.
* Hit plateaus after K=3, while Precision decreases slightly.
* Recall and F1 continue to increase slowly after K=3.
### Interpretation
The chart demonstrates the trade-off between generation time and performance metrics when using graph-constrained decoding with varying beam sizes. Increasing the beam size improves the Hit, Precision, Recall, and F1 scores, but it also increases the generation time. The most significant gains in performance are achieved when increasing the beam size from 1 to 3. After K=3, the improvements in performance are marginal, while the generation time continues to increase substantially. This suggests that a beam size of around 3 to 5 might be optimal for balancing performance and efficiency.