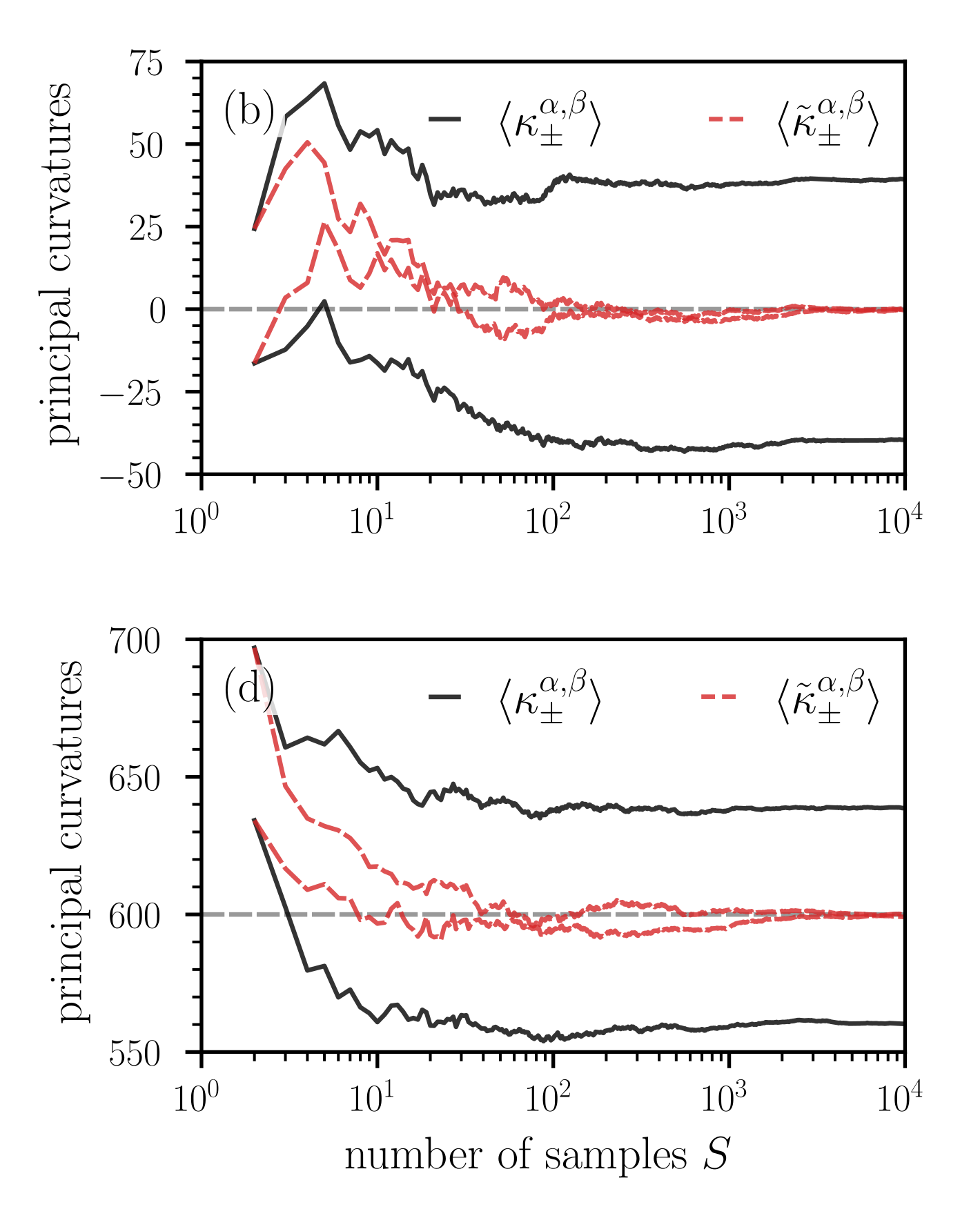
## Line Charts: Principal Curvatures vs. Number of Samples
### Overview
The image contains two line charts, (b) and (d), each plotting principal curvatures against the number of samples. Both charts display two data series: `<κ±α,β>` (solid black line) and `<κ~±α,β>` (dashed red line). The x-axis (number of samples) is on a logarithmic scale.
### Components/Axes
**Chart (b):**
* **Title:** (b) (located in the top-left corner of the chart)
* **Y-axis:** "principal curvatures" (vertical axis label). Scale ranges from -50 to 75, with tick marks at -50, -25, 0, 25, 50, and 75.
* **X-axis:** "number of samples" S (horizontal axis label). Logarithmic scale ranging from 10^0 to 10^4.
* **Legend:** Located in the top-right corner.
* Solid black line: `<κ±α,β>`
* Dashed red line: `<κ~±α,β>`
* A horizontal dashed gray line is present at y = 0.
**Chart (d):**
* **Title:** (d) (located in the top-left corner of the chart)
* **Y-axis:** "principal curvatures" (vertical axis label). Scale ranges from 550 to 700, with tick marks at 550, 600, 650, and 700.
* **X-axis:** "number of samples" S (horizontal axis label). Logarithmic scale ranging from 10^0 to 10^4.
* **Legend:** Located in the top-right corner.
* Solid black line: `<κ±α,β>`
* Dashed red line: `<κ~±α,β>`
* A horizontal dashed gray line is present at y = 600.
### Detailed Analysis
**Chart (b):**
* **`<κ±α,β>` (solid black line):** Starts at approximately -15 at x=10^0, rises sharply to a peak around 70 at x=10^1, then decreases to approximately 35 and stabilizes around x=10^2, remaining relatively constant until x=10^4.
* **`<κ~±α,β>` (dashed red line):** Starts at approximately 25 at x=10^0, rises to a peak around 50 at x=10^0.5, then decreases and oscillates around 0, stabilizing around x=10^3.
**Chart (d):**
* **`<κ±α,β>` (solid black line):** Starts at approximately 600 at x=10^0, rises to a peak around 675 at x=10^1, then decreases to approximately 635 and stabilizes around x=10^2, remaining relatively constant until x=10^4.
* **`<κ~±α,β>` (dashed red line):** Starts at approximately 630 at x=10^0, decreases to approximately 595 and oscillates around 600, stabilizing around x=10^2.
### Key Observations
* Both charts show that the principal curvatures converge as the number of samples increases.
* The `<κ±α,β>` series (solid black line) in both charts exhibits a more pronounced initial peak and subsequent stabilization compared to the `<κ~±α,β>` series (dashed red line).
* In chart (b), the `<κ~±α,β>` series oscillates around 0, suggesting a possible convergence towards zero curvature.
* In chart (d), the `<κ~±α,β>` series oscillates around 600, suggesting a possible convergence towards a curvature of 600.
### Interpretation
The charts illustrate the convergence behavior of two different measures of principal curvature, `<κ±α,β>` and `<κ~±α,β>`, as the number of samples increases. The initial fluctuations in curvature are likely due to the limited number of samples, while the stabilization at higher sample counts indicates a more reliable estimate of the true curvature. The difference in the convergence values and the initial peaks between the two curvature measures suggests that they may be sensitive to different aspects of the underlying data or calculation method. The stabilization of `<κ~±α,β>` around 0 in chart (b) could indicate a region of zero curvature, while the stabilization around 600 in chart (d) suggests a region with a constant positive curvature.