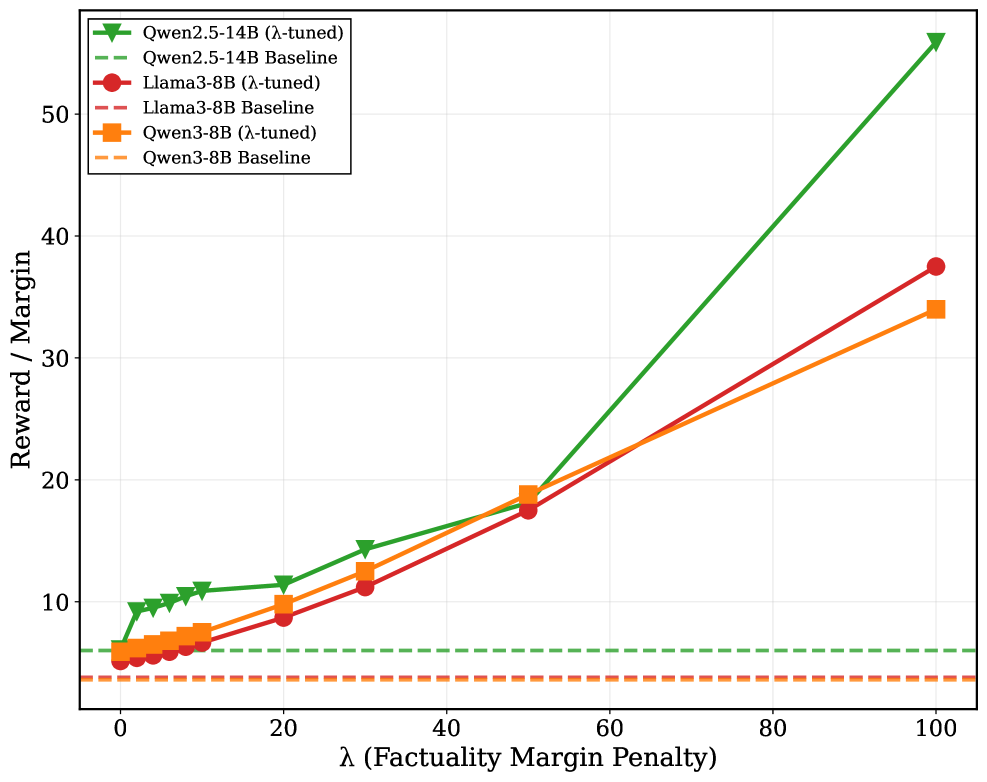
## Line Chart: Reward/Margin vs. Factuality Penalty
### Overview
This line chart depicts the relationship between a factuality margin penalty (λ) and the resulting reward/margin for several language models. The models compared are Qwen2.5-14B, Qwen3-8B, and Llama3-8B, each in both a λ-tuned and baseline configuration. The chart illustrates how performance changes as the penalty for factual inaccuracies increases.
### Components/Axes
* **X-axis:** λ (Factuality Margin Penalty). Scale ranges from 0 to 100, with markers at 0, 20, 40, 60, 80, and 100.
* **Y-axis:** Reward / Margin. Scale ranges from 0 to 60, with markers at 10, 20, 30, 40, and 50.
* **Legend:** Located in the top-left corner. Contains the following data series:
* Qwen2.5-14B (λ-tuned) - Green line with triangle markers.
* Qwen2.5-14B Baseline - Gray dashed line with circle markers.
* Llama3-8B (λ-tuned) - Red line with circle markers.
* Llama3-8B Baseline - Orange dashed line with square markers.
* Qwen3-8B (λ-tuned) - Black line with square markers.
* Qwen3-8B Baseline - Brown dashed line with diamond markers.
### Detailed Analysis
Here's a breakdown of each data series, noting trends and approximate values:
* **Qwen2.5-14B (λ-tuned) - Green:** This line shows a strong upward trend.
* λ = 0: Reward/Margin ≈ 7.
* λ = 20: Reward/Margin ≈ 11.
* λ = 40: Reward/Margin ≈ 15.
* λ = 60: Reward/Margin ≈ 23.
* λ = 80: Reward/Margin ≈ 36.
* λ = 100: Reward/Margin ≈ 53.
* **Qwen2.5-14B Baseline - Gray Dashed:** This line is relatively flat.
* λ = 0: Reward/Margin ≈ 7.
* λ = 20: Reward/Margin ≈ 8.
* λ = 40: Reward/Margin ≈ 9.
* λ = 60: Reward/Margin ≈ 10.
* λ = 80: Reward/Margin ≈ 11.
* λ = 100: Reward/Margin ≈ 12.
* **Llama3-8B (λ-tuned) - Red:** This line shows a moderate upward trend.
* λ = 0: Reward/Margin ≈ 7.
* λ = 20: Reward/Margin ≈ 11.
* λ = 40: Reward/Margin ≈ 16.
* λ = 60: Reward/Margin ≈ 22.
* λ = 80: Reward/Margin ≈ 32.
* λ = 100: Reward/Margin ≈ 36.
* **Llama3-8B Baseline - Orange Dashed:** This line is relatively flat, similar to the Qwen2.5-14B baseline.
* λ = 0: Reward/Margin ≈ 6.
* λ = 20: Reward/Margin ≈ 7.
* λ = 40: Reward/Margin ≈ 8.
* λ = 60: Reward/Margin ≈ 9.
* λ = 80: Reward/Margin ≈ 10.
* λ = 100: Reward/Margin ≈ 11.
* **Qwen3-8B (λ-tuned) - Black:** This line shows a moderate upward trend.
* λ = 0: Reward/Margin ≈ 7.
* λ = 20: Reward/Margin ≈ 10.
* λ = 40: Reward/Margin ≈ 14.
* λ = 60: Reward/Margin ≈ 18.
* λ = 80: Reward/Margin ≈ 25.
* λ = 100: Reward/Margin ≈ 32.
* **Qwen3-8B Baseline - Brown Dashed:** This line is relatively flat, similar to the other baselines.
* λ = 0: Reward/Margin ≈ 6.
* λ = 20: Reward/Margin ≈ 7.
* λ = 40: Reward/Margin ≈ 8.
* λ = 60: Reward/Margin ≈ 9.
* λ = 80: Reward/Margin ≈ 10.
* λ = 100: Reward/Margin ≈ 11.
### Key Observations
* The λ-tuned versions of all models consistently outperform their baseline counterparts across all λ values.
* Qwen2.5-14B (λ-tuned) exhibits the most significant improvement in reward/margin as λ increases, demonstrating a strong sensitivity to the factuality penalty.
* The baseline models show minimal change in reward/margin as λ increases, indicating they are largely unaffected by the factuality penalty.
* Llama3-8B (λ-tuned) and Qwen3-8B (λ-tuned) show similar performance, with moderate improvements as λ increases.
### Interpretation
The data suggests that λ-tuning is an effective method for improving the factual accuracy and overall reward/margin of these language models. The substantial increase in reward/margin for Qwen2.5-14B (λ-tuned) indicates that this model benefits significantly from being penalized for generating factually incorrect information. The flat lines for the baseline models suggest that they either already possess a reasonable level of factual accuracy or are not easily influenced by the penalty.
The relationship between the models and the penalty suggests a trade-off between fluency/creativity and factual correctness. As the penalty for factual errors increases (higher λ), the models are incentivized to prioritize accuracy over generating potentially more creative but less verifiable responses. The divergence between the tuned and baseline models highlights the importance of explicitly training models to value factual correctness. The fact that the tuned models show a clear upward trend suggests that the λ-tuning process successfully instilled this preference.