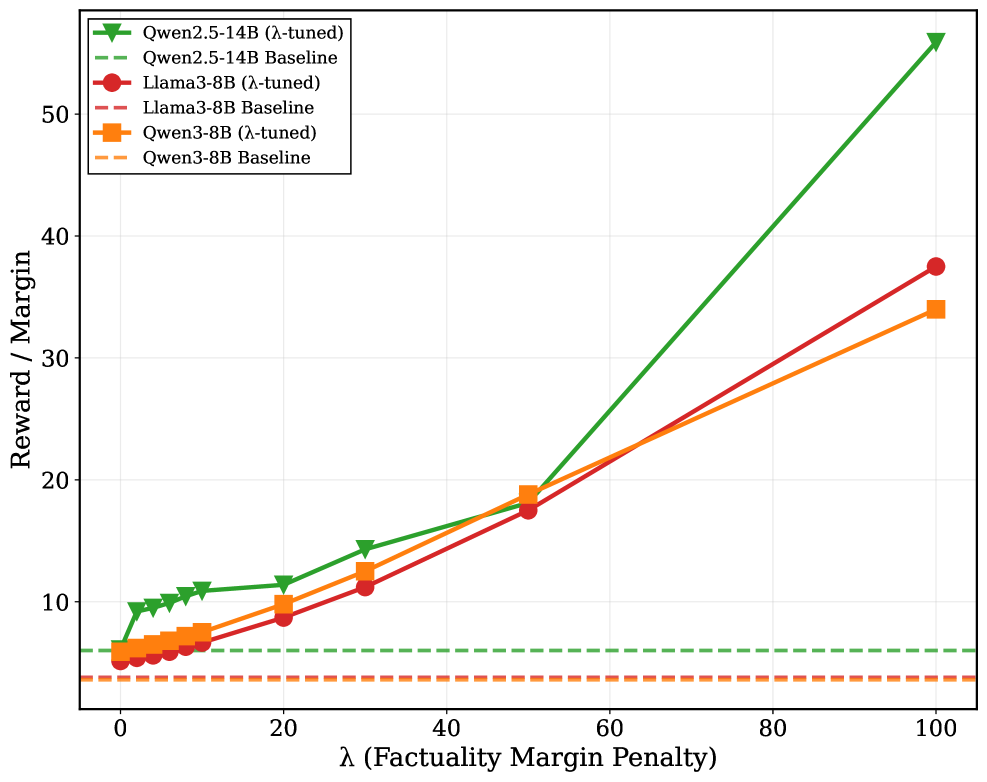
## Line Graph: Reward/Margin vs Factuality Margin Penalty (λ)
### Overview
The graph compares the performance of three language models (Qwen2.5-14B, Llama3-8B, Qwen3-8B) under two conditions: "λ-tuned" (solid lines) and "Baseline" (dashed lines). The x-axis represents the factuality margin penalty (λ), ranging from 0 to 100, while the y-axis measures "Reward / Margin" from 0 to 50. All models show performance degradation at λ=0, with improvement as λ increases.
### Components/Axes
- **X-axis**: λ (Factuality Margin Penalty) [0, 20, 40, 60, 80, 100]
- **Y-axis**: Reward / Margin [0, 10, 20, 30, 40, 50]
- **Legend**: Top-left corner, color-coded for:
- Qwen2.5-14B (green)
- Llama3-8B (red)
- Qwen3-8B (orange)
- **Line styles**: Solid = λ-tuned, Dashed = Baseline
### Detailed Analysis
1. **Qwen2.5-14B**:
- **Tuned (solid green)**: Starts at ~5 (λ=0), rises sharply to ~55 (λ=100).
- **Baseline (dashed green)**: Flat at ~5 across all λ values.
2. **Llama3-8B**:
- **Tuned (solid red)**: Starts at ~5 (λ=0), increases gradually to ~38 (λ=100).
- **Baseline (dashed red)**: Flat at ~5 across all λ values.
3. **Qwen3-8B**:
- **Tuned (solid orange)**: Starts at ~5 (λ=0), rises steadily to ~34 (λ=100).
- **Baseline (dashed orange)**: Flat at ~5 across all λ values.
### Key Observations
- All tuned models show **positive correlation** between λ and reward/margin, while baselines remain constant.
- **Qwen2.5-14B** exhibits the steepest slope (≈0.5 reward/unit λ), outperforming others at λ=100.
- **Llama3-8B** has the second-highest reward at λ=100 (~38), followed by Qwen3-8B (~34).
- Baseline lines for all models are **horizontal at y=5**, indicating no improvement without tuning.
### Interpretation
The data demonstrates that increasing the factuality margin penalty (λ) enhances model performance for all tuned variants. Qwen2.5-14B benefits most from higher λ values, suggesting superior sensitivity to factuality constraints. The flat baselines confirm that tuning is critical for leveraging λ's effects. This implies that models optimized for factual accuracy (via λ-tuning) can achieve significantly higher reward/margin ratios, with Qwen2.5-14B being the most responsive to this optimization.