## Bar Charts: Command Frequency Comparison for CiteAgent with GPT-4o and Claude 3 Opus
### Overview
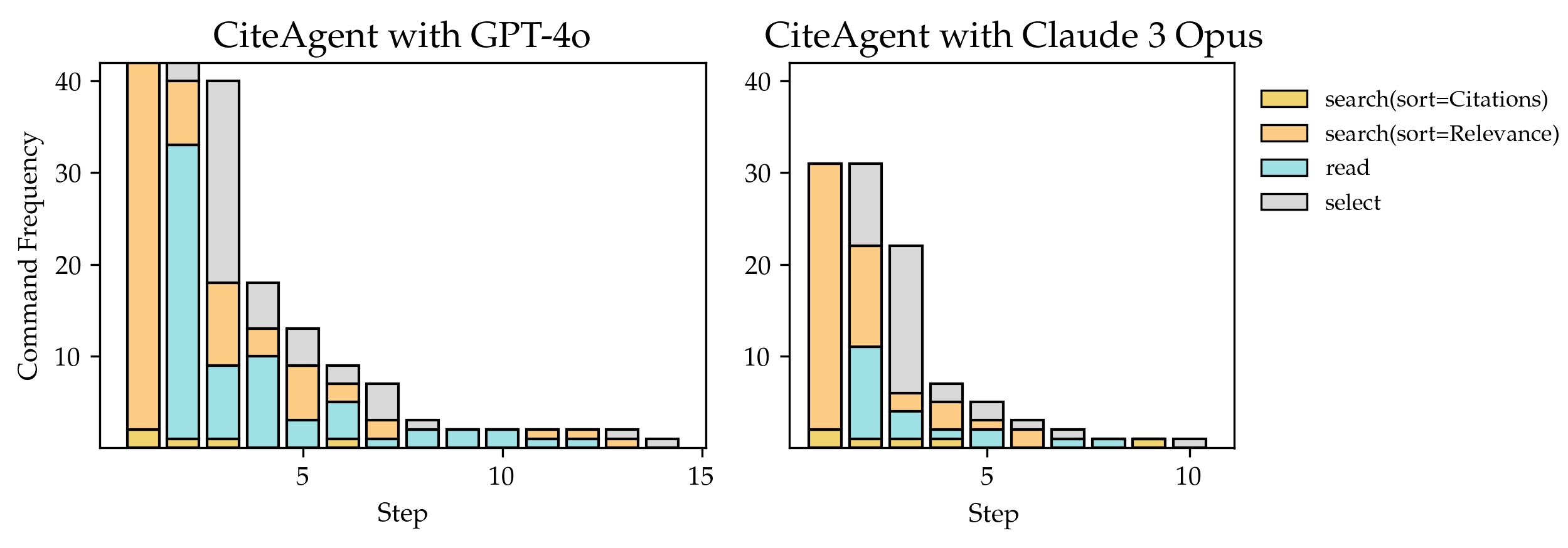
The image contains two side-by-side bar charts comparing command frequencies for two AI agents: "CiteAgent with GPT-4o" (left) and "CiteAgent with Claude 3 Opus" (right). Each chart visualizes the distribution of four command types across 15 steps, with frequency values ranging from 0 to 40.
### Components/Axes
- **X-axis (Step)**: Labeled "Step," with markers at intervals of 5 (0, 5, 10, 15).
- **Y-axis (Command Frequency)**: Labeled "Command Frequency," scaled from 0 to 40.
- **Legend**: Positioned on the right of each chart, with four color-coded categories:
- Yellow: `search(sort=Citations)`
- Orange: `search(sort=Relevance)`
- Teal: `read`
- Gray: `select`
### Detailed Analysis
#### CiteAgent with GPT-4o (Left Chart)
- **Step 0**:
- `search(sort=Citations)`: ~40 (yellow)
- `search(sort=Relevance)`: ~35 (orange)
- `read`: ~33 (teal)
- `select`: ~2 (gray)
- **Step 5**:
- `search(sort=Citations)`: ~15 (yellow)
- `search(sort=Relevance)`: ~10 (orange)
- `read`: ~5 (teal)
- `select`: ~3 (gray)
- **Step 10**:
- All commands drop to ~1–2 (yellow/orange/teal/gray).
- **Step 15**:
- Minimal activity (~1 for gray `select`).
#### CiteAgent with Claude 3 Opus (Right Chart)
- **Step 0**:
- `search(sort=Citations)`: ~30 (yellow)
- `search(sort=Relevance)`: ~25 (orange)
- `read`: ~10 (teal)
- `select`: ~5 (gray)
- **Step 5**:
- `search(sort=Citations)`: ~5 (yellow)
- `search(sort=Relevance)`: ~3 (orange)
- `read`: ~2 (teal)
- `select`: ~4 (gray)
- **Step 10**:
- All commands drop to ~1–2 (yellow/orange/teal/gray).
- **Step 15**:
- Minimal activity (~1 for gray `select`).
### Key Observations
1. **Dominant Commands**:
- GPT-4o prioritizes `search(sort=Citations)` and `read` at Step 0, with frequencies ~40 and ~33, respectively.
- Claude 3 Opus emphasizes `search(sort=Citations)` (~30) and `search(sort=Relevance)` (~25) at Step 0.
2. **Decline Trends**:
- Both agents show steep declines in command frequency as steps increase, with near-zero activity by Step 15.
3. **Select Command**:
- GPT-4o’s `select` command remains negligible (~2 at Step 0), while Claude 3 Opus shows moderate use (~5 at Step 0).
### Interpretation
The data suggests that **GPT-4o** is optimized for citation-based searches and reading tasks, with high initial frequencies that decay rapidly. In contrast, **Claude 3 Opus** balances citation and relevance-based searches but allocates more resources to the `select` command. The sharp decline in activity across steps implies that both agents may struggle with sustained task execution or face diminishing returns over time. The disparity in `select` usage hints at differing strategies: GPT-4o focuses on information retrieval, while Claude 3 Opus integrates selection as a core workflow component.