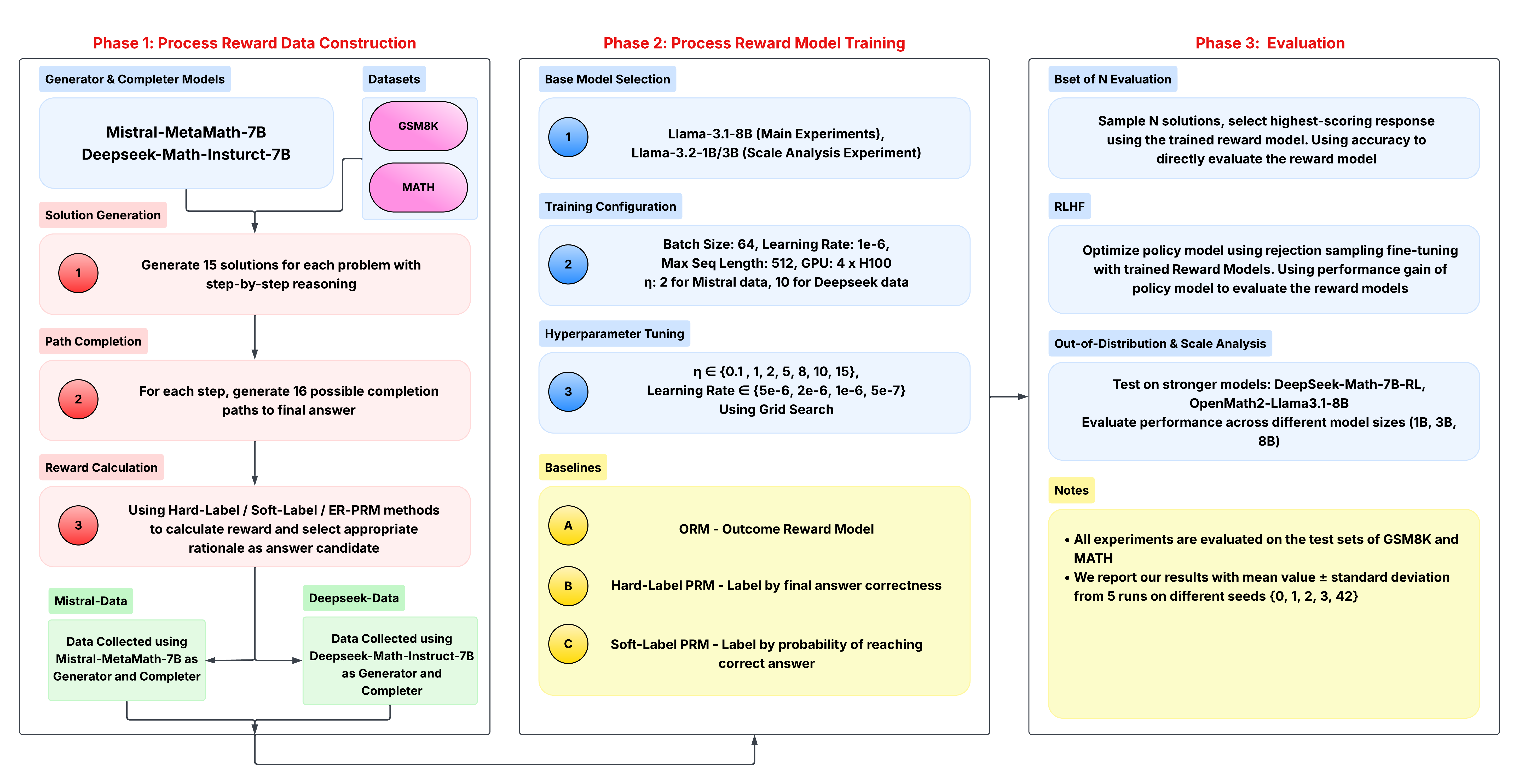
## Flowchart: Multi-Phase Reward Model Development Pipeline
### Overview
The flowchart depicts a three-phase technical pipeline for developing and evaluating reward models for mathematical reasoning tasks. It combines model training, reward calculation methodologies, and evaluation protocols using large language models (LLMs) like Mistral, DeepSeek, and Llama.
### Components/Axes
**Phase 1: Process Reward Data Construction**
- **Generator & Completer Models**:
- Mistral-MetaMath-7B
- Deepseek-Math-Instruct-7B
- **Datasets**:
- GSM8K (purple)
- MATH (pink)
- **Key Steps**:
1. Solution Generation (15 solutions/problem)
2. Path Completion (16 paths/step)
3. Reward Calculation (Hard/Soft/ERPRM methods)
**Phase 2: Process Reward Model Training**
- **Base Models**:
- Llama-3.1-8B (Main Experiments)
- Llama-3.2-1B/3B (Scale Analysis)
- **Training Config**:
- Batch Size: 64
- Learning Rate: 1e-6
- Max Seq Length: 512
- GPU: 4x H100
- **Hyperparameters**:
- η ∈ {0.1, 1, 2, 5, 8, 10, 15}
- Learning Rate ∈ {5e-6, 2e-6, 1e-6, 5e-7}
- **Baselines**:
- ORM (Outcome Reward Model)
- Hard-Label PRM (Answer correctness)
- Soft-Label PRM (Path probability)
**Phase 3: Evaluation**
- **Bset of N Evaluation**:
- Sample N solutions
- Select highest-scoring response
- Direct accuracy evaluation
- **RLHF**:
- Rejection sampling fine-tuning
- Performance gain metric
- **Out-of-Distribution Analysis**:
- Test on stronger models:
- DeepSeek-Math-7B-RL
- OpenMath2-Llama3.1-8B
- Evaluate across model sizes (1B, 3B, 8B)
### Detailed Analysis
**Phase 1 Details**
- **Solution Generation**: Both Mistral and DeepSeek models generate 15 step-by-step solutions per problem
- **Path Completion**: For each solution step, 16 possible completion paths are generated
- **Reward Calculation**: Three methods used:
- Hard-Label PRM: Final answer correctness
- Soft-Label PRM: Probability of reaching correct answer
- ERPRM: Error pattern recognition
**Phase 2 Details**
- **Training Configuration**:
- Optimized for Mistral data (η=2) and DeepSeek data (η=10)
- GPU configuration suggests high-performance training setup
- **Hyperparameter Tuning**:
- Grid search across multiple learning rates and η values
- Suggests systematic optimization approach
**Phase 3 Details**
- **Evaluation Protocols**:
- Direct accuracy measurement via Bset of N sampling
- RLHF fine-tuning for policy improvement
- Cross-model evaluation on stronger architectures
- **Testing Framework**:
- Uses GSM8K and MATH test sets
- Reports mean ± std dev from 5 seed runs (seeds: 0,1,2,3,42)
### Key Observations
1. **Model Agnosticism**: The pipeline works with multiple LLM architectures (Mistral, DeepSeek, Llama)
2. **Multi-Method Reward Calculation**: Combines answer correctness, path probability, and error pattern analysis
3. **Scalability Focus**: Includes both main experiments (8B models) and scale analysis (1B/3B models)
4. **Robust Evaluation**: Uses multiple evaluation metrics and cross-model testing
5. **Reproducibility**: Explicit seed values and testing framework details
### Interpretation
This pipeline demonstrates a comprehensive approach to reward model development for mathematical reasoning tasks. The three-phase structure ensures:
1. **Data Quality**: Multiple solution paths and PRM methods create diverse training data
2. **Model Optimization**: Systematic hyperparameter tuning across different architectures
3. **Evaluation Rigor**: Combines direct accuracy measurement with cross-model benchmarking
The use of both hard and soft labels in reward calculation suggests an attempt to capture both final answer correctness and reasoning process quality. The inclusion of scale analysis (1B/3B/8B models) indicates an interest in understanding how model size affects reward model performance. The explicit reporting of standard deviations from multiple seeds emphasizes the importance of statistical robustness in the evaluation process.