TECHNICAL ASSET FINGERPRINT
f9fd85238153f85b2c50e1cb
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: healer-alpha-free VERSION 1
RUNTIME: free/openrouter/healer-alpha
INTEL_VERIFIED
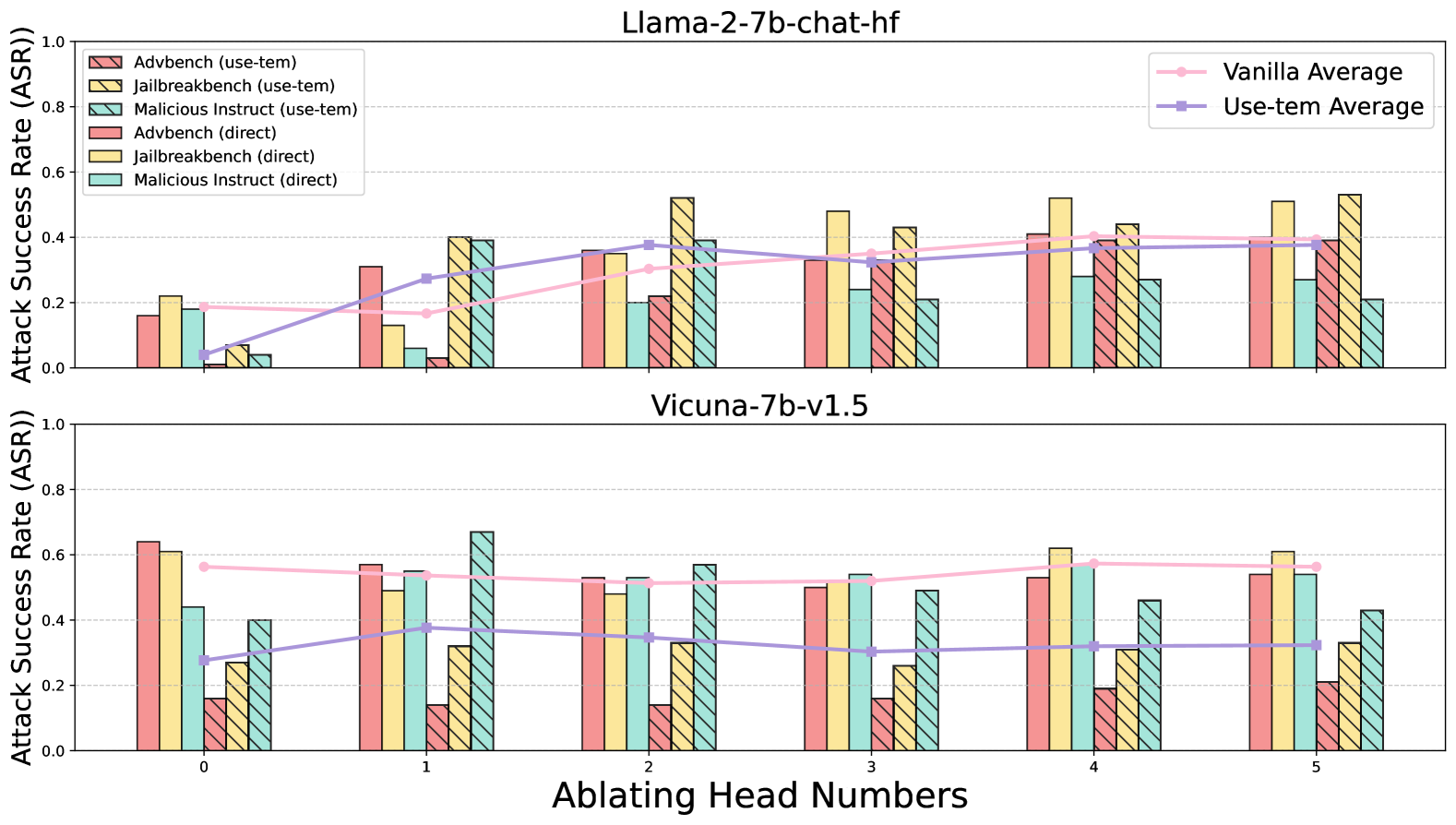
## Bar Chart with Line Overlays: Attack Success Rate (ASR) vs. Ablating Head Numbers
### Overview
The image displays two vertically stacked bar charts, each comparing the Attack Success Rate (ASR) of different attack methods across varying numbers of ablated attention heads for two distinct language models. The top chart is for the model "Llama-2-7b-chat-hf," and the bottom chart is for "Vicuna-7b-v1.5." Each chart includes grouped bars for six different attack scenarios and two overlaid line graphs representing average performance.
### Components/Axes
* **Chart Titles:**
* Top Chart: `Llama-2-7b-chat-hf`
* Bottom Chart: `Vicuna-7b-v1.5`
* **Y-Axis (Both Charts):** Label is `Attack Success Rate (ASR)`. Scale ranges from 0.0 to 1.0, with major gridlines at 0.2 intervals.
* **X-Axis (Bottom Chart):** Label is `Ablating Head Numbers`. Categories are discrete integers: `0`, `1`, `2`, `3`, `4`, `5`.
* **Primary Legend (Top-Left of Top Chart):** Defines six bar series.
1. `Advbench (use-tem)`: Pink bar with diagonal hatching (top-left to bottom-right).
2. `Jailbreakbench (use-tem)`: Yellow bar with diagonal hatching (top-left to bottom-right).
3. `Malicious Instruct (use-tem)`: Teal bar with diagonal hatching (top-left to bottom-right).
4. `Advbench (direct)`: Solid pink bar.
5. `Jailbreakbench (direct)`: Solid yellow bar.
6. `Malicious Instruct (direct)`: Solid teal bar.
* **Secondary Legend (Top-Right of Top Chart):** Defines two line series.
1. `Vanilla Average`: Pink line with circular markers.
2. `Use-tem Average`: Purple line with square markers.
### Detailed Analysis
**Data Series Trends & Approximate Values:**
**Top Chart: Llama-2-7b-chat-hf**
* **Vanilla Average (Pink Line):** Shows a gradual upward trend. Starts at ~0.19 (Head 0), dips slightly to ~0.17 (Head 1), then rises steadily to ~0.40 (Head 5).
* **Use-tem Average (Purple Line):** Shows a strong upward trend. Starts very low at ~0.04 (Head 0), rises sharply to ~0.28 (Head 1), and continues increasing to plateau around ~0.38-0.39 (Heads 2-5).
* **Bar Data (Approximate ASR per Ablating Head Number):**
* **Head 0:** Direct methods are higher than use-tem. Advbench (direct) ~0.16, Jailbreakbench (direct) ~0.22, Malicious Instruct (direct) ~0.18. Use-tem methods are all below 0.1.
* **Head 1:** Direct methods remain moderate. Use-tem methods increase significantly, with Jailbreakbench (use-tem) ~0.40 and Malicious Instruct (use-tem) ~0.39.
* **Head 2:** Jailbreakbench (use-tem) peaks at ~0.52. Other use-tem methods are ~0.36-0.39. Direct methods range from ~0.20 to ~0.35.
* **Head 3:** Jailbreakbench (direct) peaks at ~0.48. Use-tem methods are clustered between ~0.21 and ~0.43.
* **Head 4:** Jailbreakbench (direct) is high at ~0.52. Use-tem methods are between ~0.27 and ~0.44.
* **Head 5:** Jailbreakbench (use-tem) is highest at ~0.53. Direct methods are between ~0.21 and ~0.39.
**Bottom Chart: Vicuna-7b-v1.5**
* **Vanilla Average (Pink Line):** Relatively flat, slight downward trend. Starts at ~0.57 (Head 0), ends at ~0.57 (Head 5), with a minor dip in between.
* **Use-tem Average (Purple Line):** Shows a slight upward trend. Starts at ~0.28 (Head 0), rises to ~0.38 (Head 1), then fluctuates between ~0.31 and ~0.35 for Heads 2-5.
* **Bar Data (Approximate ASR per Ablating Head Number):**
* **Head 0:** Direct methods are high: Advbench (direct) ~0.64, Jailbreakbench (direct) ~0.61. Use-tem methods are lower, ranging from ~0.16 to ~0.44.
* **Head 1:** Malicious Instruct (use-tem) peaks at ~0.67. Direct methods are between ~0.49 and ~0.57.
* **Head 2:** Malicious Instruct (use-tem) is high at ~0.57. Direct methods are between ~0.48 and ~0.52.
* **Head 3:** Direct methods are clustered around ~0.50-0.54. Use-tem methods are lower, between ~0.16 and ~0.49.
* **Head 4:** Jailbreakbench (direct) peaks at ~0.62. Use-tem methods range from ~0.19 to ~0.56.
* **Head 5:** Jailbreakbench (direct) is high at ~0.61. Use-tem methods range from ~0.21 to ~0.54.
### Key Observations
1. **Model Sensitivity:** The Vicuna model (bottom chart) generally exhibits higher baseline Attack Success Rates (especially for direct methods at Head 0) compared to the Llama model.
2. **Impact of "use-tem":** For the Llama model, the "use-tem" average line starts near zero and shows a strong positive correlation with the number of ablated heads. For Vicuna, the "use-tem" average is more stable but consistently below the "Vanilla Average."
3. **Benchmark Variability:** The `Jailbreakbench` benchmark (both direct and use-tem) frequently yields the highest ASR values across both models and many head ablation numbers.
4. **Ablation Effect:** There is no uniform monotonic trend for ASR as head numbers increase. Performance varies significantly by model, benchmark, and attack method (direct vs. use-tem), suggesting the importance of specific attention heads is highly context-dependent.
5. **Outlier:** The `Malicious Instruct (use-tem)` bar for Vicuna at Ablating Head Number 1 is a notable outlier, reaching the highest ASR (~0.67) in the entire dataset.
### Interpretation
This data visualizes an experiment probing the robustness of two Large Language Models (LLMs) against adversarial attacks when specific attention heads are ablated (likely meaning their outputs are zeroed or modified). The "Attack Success Rate" measures how often an attack bypasses the model's safety alignment.
The key finding is that the effect of ablating attention heads is **not uniform** and is **highly model- and task-specific**. For the Llama model, using the "use-tem" attack method becomes dramatically more successful as more heads are ablated, suggesting those heads may play a critical role in its safety mechanisms against that specific attack type. In contrast, the Vicuna model's safety appears less dependent on the ablated heads for the "Vanilla" (likely standard) attacks, as its average line is flat. However, its vulnerability to specific benchmarks like `Jailbreakbench` remains high regardless of head ablation.
The stark difference between the "direct" and "use-tem" methods, and their varying responses to ablation, implies that different attack vectors exploit different model vulnerabilities. The high performance of `Jailbreakbench` suggests it is a particularly effective suite of attacks for these models. Overall, the charts argue that model safety is a complex function of specific internal components (attention heads) and the precise nature of the adversarial input, necessitating nuanced defense strategies rather than broad-stroke interventions.
DECODING INTELLIGENCE...