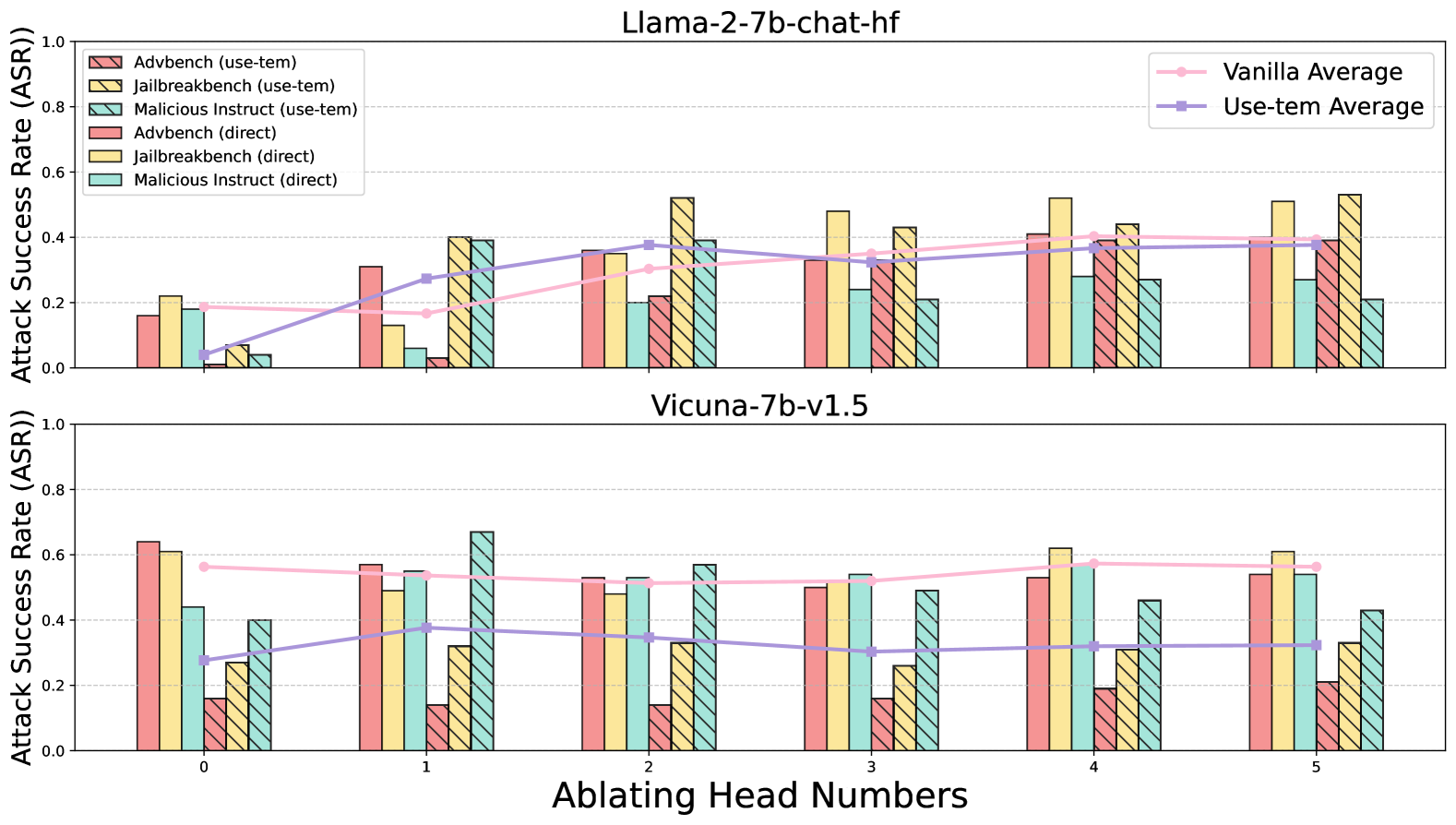
## Bar Chart: Attack Success Rate (ASR) Comparison Across Models and Attack Methods
### Overview
The image presents two stacked bar charts comparing attack success rates (ASR) for adversarial attack methods on two language models: **Llama-2-7b-chat-hf** (top) and **Vicuna-7b-v1.5** (bottom). Each chart evaluates six attack methods across five ablated head numbers (0–5). Two average lines—**Vanilla Average** (pink) and **Use-tem Average** (purple)—are overlaid on each sub-chart.
---
### Components/Axes
- **X-Axis**: "Ablating Head Numbers" (0–5, evenly spaced).
- **Y-Axis**: "Attack Success Rate (ASR)" (0.0–1.0, increments of 0.2).
- **Legends**:
1. **Attack Methods** (top-right):
- **Advbench (use-tem)**: Red with diagonal stripes.
- **Jailbreakbench (use-tem)**: Yellow with diagonal stripes.
- **Malicious Instruct (use-tem)**: Green with diagonal stripes.
- **Advbench (direct)**: Red with solid fill.
- **Jailbreakbench (direct)**: Yellow with solid fill.
- **Malicious Instruct (direct)**: Green with solid fill.
2. **Average Lines** (top-right):
- **Vanilla Average**: Pink line.
- **Use-tem Average**: Purple line.
---
### Detailed Analysis
#### Llama-2-7b-chat-hf (Top Chart)
- **Advbench (use-tem)**: ASR increases from ~0.15 (head 0) to ~0.35 (head 5).
- **Jailbreakbench (use-tem)**: Peaks at ~0.55 (head 2), then drops to ~0.45 (head 5).
- **Malicious Instruct (use-tem)**: Rises to ~0.4 (head 2), then declines to ~0.2 (head 5).
- **Vanilla Average**: ~0.25 across all heads.
- **Use-tem Average**: ~0.35 across all heads.
#### Vicuna-7b-v1.5 (Bottom Chart)
- **Advbench (use-tem)**: Starts at ~0.6 (head 0), drops to ~0.55 (head 1), fluctuates between ~0.5–0.55.
- **Jailbreakbench (use-tem)**: Peaks at ~0.5 (head 1), then declines to ~0.3 (head 5).
- **Malicious Instruct (use-tem)**: Peaks at ~0.6 (head 1), then drops to ~0.4 (head 5).
- **Vanilla Average**: ~0.55 across all heads.
- **Use-tem Average**: ~0.35 across all heads.
---
### Key Observations
1. **Model-Specific Trends**:
- **Llama-2**: Jailbreakbench (use-tem) dominates ASR, while Malicious Instruct (use-tem) shows a sharp decline after head 2.
- **Vicuna-7b**: Advbench (use-tem) starts strong but declines, while Malicious Instruct (use-tem) peaks early.
2. **Average Lines**:
- **Vanilla Average** consistently exceeds **Use-tem Average** in both models, suggesting vanilla methods are generally more effective.
3. **Anomalies**:
- Malicious Instruct (use-tem) in Llama-2 shows a significant drop after head 2, possibly indicating model-specific vulnerabilities.
---
### Interpretation
The data highlights that attack effectiveness varies by model architecture and head number. **Jailbreakbench (use-tem)** is most effective on Llama-2, while **Advbench (use-tem)** performs better on Vicuna-7b initially. The **Use-tem Average** consistently underperforms the **Vanilla Average**, implying that templated methods may be less robust. The sharp declines in Malicious Instruct (use-tem) after specific heads suggest potential weaknesses in model design or training. These trends underscore the importance of head-specific vulnerabilities in adversarial robustness.