\n
## Bar Charts: LLM Performance Comparison
### Overview
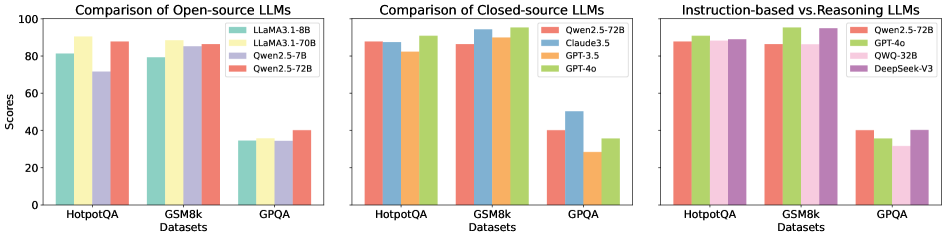
The image presents three side-by-side bar charts comparing the performance of various Large Language Models (LLMs) across three datasets: HotpotQA, GSM8k, and GPQA. The charts are categorized into Open-source LLMs, Closed-source LLMs, and a comparison of Instruction-based vs. Reasoning LLMs. The y-axis represents "Scores," ranging from 0 to 100. The x-axis represents the datasets.
### Components/Axes
* **Y-axis:** "Scores" (0 to 100, linear scale)
* **X-axis:** "Datasets" (HotpotQA, GSM8k, GPQA)
* **Chart 1 (Open-source LLMs):**
* Legend:
* LLaMA3-1.8B (Light Blue)
* LLaMA3-70B (Pale Green)
* Qwen2.5-7B (Light Orange)
* Qwen2.5-72B (Light Red)
* **Chart 2 (Closed-source LLMs):**
* Legend:
* Qwen2.5-72B (Light Orange)
* Claude3.5 (Pale Yellow)
* GPT-3.5 (Light Brown)
* GPT-4o (Light Purple)
* **Chart 3 (Instruction-based vs. Reasoning LLMs):**
* Legend:
* Qwen2.5-72B (Light Orange)
* GPT-3.5 (Light Brown)
* QWO-32B (Light Green)
* DeepSeek-V3 (Dark Green)
### Detailed Analysis
**Chart 1: Comparison of Open-source LLMs**
* **HotpotQA:** LLaMA3-1.8B scores approximately 84. LLaMA3-70B scores approximately 88. Qwen2.5-7B scores approximately 86. Qwen2.5-72B scores approximately 89.
* **GSM8k:** LLaMA3-1.8B scores approximately 86. LLaMA3-70B scores approximately 92. Qwen2.5-7B scores approximately 88. Qwen2.5-72B scores approximately 91.
* **GPQA:** LLaMA3-1.8B scores approximately 34. LLaMA3-70B scores approximately 38. Qwen2.5-7B scores approximately 36. Qwen2.5-72B scores approximately 42.
**Chart 2: Comparison of Closed-source LLMs**
* **HotpotQA:** Qwen2.5-72B scores approximately 90. Claude3.5 scores approximately 94. GPT-3.5 scores approximately 88. GPT-4o scores approximately 96.
* **GSM8k:** Qwen2.5-72B scores approximately 92. Claude3.5 scores approximately 95. GPT-3.5 scores approximately 90. GPT-4o scores approximately 97.
* **GPQA:** Qwen2.5-72B scores approximately 40. Claude3.5 scores approximately 44. GPT-3.5 scores approximately 32. GPT-4o scores approximately 46.
**Chart 3: Instruction-based vs. Reasoning LLMs**
* **HotpotQA:** Qwen2.5-72B scores approximately 90. GPT-3.5 scores approximately 88. QWO-32B scores approximately 92. DeepSeek-V3 scores approximately 94.
* **GSM8k:** Qwen2.5-72B scores approximately 92. GPT-3.5 scores approximately 90. QWO-32B scores approximately 94. DeepSeek-V3 scores approximately 96.
* **GPQA:** Qwen2.5-72B scores approximately 38. GPT-3.5 scores approximately 32. QWO-32B scores approximately 36. DeepSeek-V3 scores approximately 40.
### Key Observations
* GPT-4o consistently achieves the highest scores across all datasets in the Closed-source LLM comparison.
* LLaMA3-70B generally outperforms LLaMA3-1.8B across all datasets.
* DeepSeek-V3 consistently achieves the highest scores across all datasets in the Instruction-based vs. Reasoning LLMs comparison.
* Performance on GPQA is significantly lower than on HotpotQA and GSM8k for all models.
* Qwen2.5-72B performs well across all charts, often being competitive with larger models.
### Interpretation
The data suggests that model size and architecture significantly impact performance on these LLM benchmarks. Larger models (e.g., LLaMA3-70B, GPT-4o, DeepSeek-V3) generally achieve higher scores. The consistent high performance of GPT-4o and DeepSeek-V3 indicates their superior capabilities in question answering and reasoning tasks. The lower scores on the GPQA dataset suggest that this dataset presents a greater challenge for the models, potentially due to its specific characteristics or complexity. The comparison between open-source and closed-source models highlights the advancements made by proprietary models, although open-source models are rapidly improving, as demonstrated by the performance of Qwen2.5-72B and LLaMA3-70B. The final chart suggests that models specifically designed for instruction-following and reasoning (like DeepSeek-V3 and QWO-32B) can outperform general-purpose models (like GPT-3.5) on these tasks. The consistent trends across datasets suggest the results are not random and reflect genuine differences in model capabilities.