## Bar Chart: Comparison of LLMs Across Datasets
### Overview
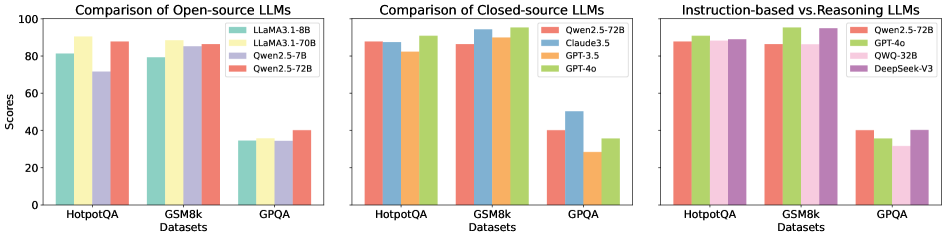
The image contains three grouped bar charts comparing the performance of various large language models (LLMs) across three datasets: **HotpotQA**, **GSM8k**, and **GPQA**. Each chart focuses on a different category of LLMs:
1. **Open-source LLMs**
2. **Closed-source LLMs**
3. **Instruction-based vs. Reasoning LLMs**
The y-axis represents scores (0–100), and the x-axis lists datasets. Legends on the right map colors to specific models.
---
### Components/Axes
#### Labels and Legends
- **X-axis (Datasets)**:
- HotpotQA
- GSM8k
- GPQA
- **Y-axis (Scores)**:
- Scale: 0 to 100 (increments of 20)
- **Legends**:
- **Open-source LLMs**:
- LLaMA 3.1-8B (teal)
- LLaMA 3.1-70B (yellow)
- Qwen 2.5-72B (red)
- GPQA (purple)
- **Closed-source LLMs**:
- Qwen 2.5-72B (red)
- Claude 3.5 (blue)
- GPT-3.5 (orange)
- GPT-4o (green)
- **Instruction-based vs. Reasoning LLMs**:
- Qwen 2.5-72B (red)
- GPT-4o (green)
- QWQ-32B (pink)
- DeepSeek-V3 (purple)
#### Spatial Grounding
- Legends are positioned on the **right** of each chart.
- Bars are grouped by dataset, with colors matching the legend labels.
---
### Detailed Analysis
#### Open-source LLMs
- **HotpotQA**:
- LLaMA 3.1-8B: ~80
- LLaMA 3.1-70B: ~90
- Qwen 2.5-72B: ~85
- GPQA: ~35
- **GSM8k**:
- LLaMA 3.1-8B: ~80
- LLaMA 3.1-70B: ~85
- Qwen 2.5-72B: ~85
- GPQA: ~35
- **GPQA**:
- All models score ~35 (lowest performance).
#### Closed-source LLMs
- **HotpotQA**:
- Qwen 2.5-72B: ~85
- Claude 3.5: ~88
- GPT-3.5: ~82
- GPT-4o: ~90
- **GSM8k**:
- Qwen 2.5-72B: ~85
- Claude 3.5: ~90
- GPT-3.5: ~82
- GPT-4o: ~90
- **GPQA**:
- Qwen 2.5-72B: ~40
- Claude 3.5: ~50
- GPT-3.5: ~30
- GPT-4o: ~35
#### Instruction-based vs. Reasoning LLMs
- **HotpotQA**:
- Qwen 2.5-72B: ~85
- GPT-4o: ~90
- QWQ-32B: ~88
- DeepSeek-V3: ~88
- **GSM8k**:
- Qwen 2.5-72B: ~85
- GPT-4o: ~90
- QWQ-32B: ~88
- DeepSeek-V3: ~90
- **GPQA**:
- Qwen 2.5-72B: ~40
- GPT-4o: ~35
- QWQ-32B: ~30
- DeepSeek-V3: ~40
---
### Key Observations
1. **Open-source models** (LLaMA, Qwen) perform well on **HotpotQA** and **GSM8k** but struggle with **GPQA** (scores ~35).
2. **Closed-source models** (GPT-4o, Claude 3.5) consistently outperform open-source models, with **GPT-4o** achieving the highest scores (~90) across datasets.
3. **Instruction-based models** (GPT-4o, DeepSeek-V3) dominate **GSM8k** and **HotpotQA**, while **reasoning models** (Qwen, QWQ) lag slightly.
4. **GPQA** is the most challenging dataset, with all models scoring below 50.
---
### Interpretation
- **Performance Trends**:
- Closed-source models (e.g., GPT-4o) leverage advanced architectures and training data, resulting in higher scores.
- Open-source models (e.g., LLaMA) show diminishing returns with larger parameter sizes (8B vs. 70B) on GPQA, suggesting architectural limitations.
- Instruction-based models (GPT-4o, DeepSeek-V3) excel in reasoning tasks (GSM8k), while reasoning-focused models (Qwen, QWQ) underperform in GPQA.
- **Anomalies**:
- GPQA scores are uniformly low, indicating it tests niche or complex reasoning not fully addressed by current LLMs.
- QWQ-32B (reasoning model) underperforms in GPQA despite its specialization, suggesting dataset-specific weaknesses.
- **Implications**:
- Closed-source models remain the benchmark for high-stakes reasoning tasks.
- Open-source models require architectural improvements (e.g., better parameter efficiency) to compete with closed-source counterparts.
- GPQA highlights a gap in evaluating multi-step reasoning, as no model achieves >50.
This analysis underscores the trade-offs between open-source accessibility and closed-source performance, with GPQA serving as a critical benchmark for future LLM development.