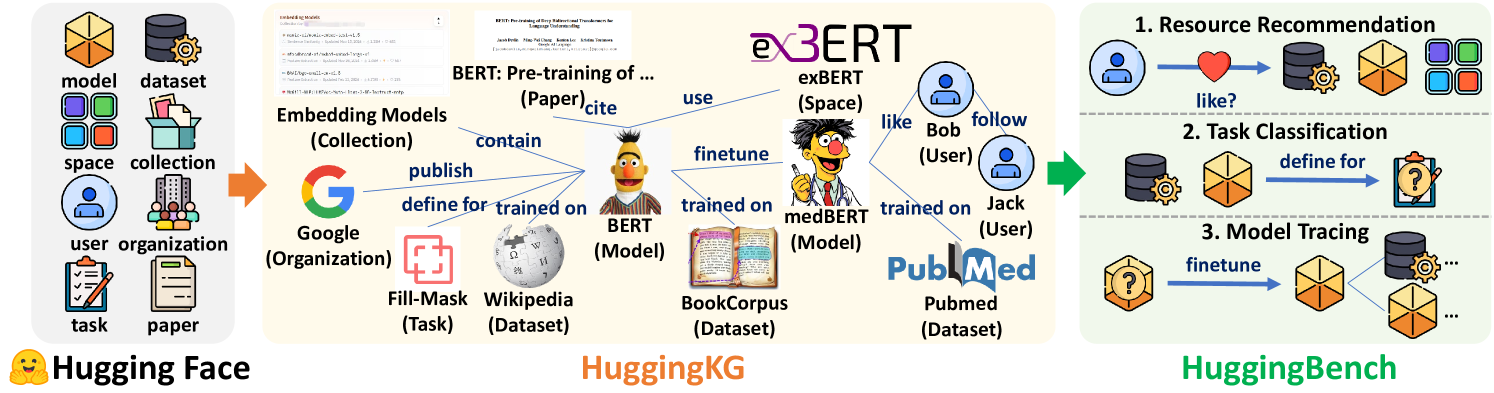
## Diagram: Hugging Face Ecosystem Workflow
### Overview
The diagram illustrates a three-stage workflow for model development and deployment within the Hugging Face ecosystem. It connects foundational elements (models, datasets, users) to advanced applications (resource recommendation, task classification, model tracing) through intermediate knowledge graphs and fine-tuning processes.
### Components/Axes
#### Key Elements:
1. **Hugging Face (Left Section)**
- **Icons/Labels**:
- `model` (3D cube), `dataset` (database), `space` (4-colored squares), `collection` (folder), `user` (person icon), `organization` (building), `task` (notebook), `paper` (document).
- **Flow**: Arrows point to `HuggingKG` (center) with labels like `publish`, `define for`, `trained on`, and `contain`.
2. **HuggingKG (Center Section)**
- **Models/Datasets**:
- `BERT` (pre-training), `ex3ERT` (space), `medBERT` (model), `PubMed` (dataset).
- **Relationships**:
- `trained on` (BERT → BookCorpus), `fine-tune` (ex3ERT → medBERT), `trained on` (medBERT → PubMed).
- **Icons**: Sesame Street characters (Bert, Ernie) represent model spaces.
3. **HuggingBench (Right Section)**
- **Three Stages**:
1. **Resource Recommendation**: User (`Bob`) interacts with `dataset`/`model` via `like?`.
2. **Task Classification**: `dataset` → `define for` → `task` (notebook).
3. **Model Tracing**: `dataset` → `fine-tune` → `model` (3D cube).
#### Arrows and Relationships:
- **HuggingKG**:
- `Google` (organization) → `Fill-Mask` (task) → `Wikipedia` (dataset).
- `BERT` (model) → `BookCorpus` (dataset).
- **HuggingBench**:
- `like?` (heart icon) → `dataset`/`model`.
- `define for` → `task` (notebook).
- `fine-tune` → `model` (3D cube).
### Detailed Analysis
- **Textual Labels**:
- All labels are in English. No non-English text detected.
- Critical labels include:
- `BERT: Pre-training of ... (Paper)` (top-center).
- `ex3ERT (Space)` (center-right).
- `medBERT (Model)` (center-right).
- `PubMed (Dataset)` (bottom-right).
- **Flow Direction**:
- Left (Hugging Face) → Center (HuggingKG) → Right (HuggingBench).
- Arrows indicate dependencies (e.g., `trained on`, `fine-tune`).
### Key Observations
1. **Modular Design**:
- HuggingKG acts as a bridge between raw data (Hugging Face) and applied workflows (HuggingBench).
2. **User-Centric Workflow**:
- Users (`Bob`, `Jack`) drive model selection and fine-tuning via interactions (`like?`, `follow`).
3. **Data Provenance**:
- Datasets like `BookCorpus` and `PubMed` are explicitly linked to models (`BERT`, `medBERT`).
4. **Sesame Street Imagery**:
- Characters (Bert, Ernie) symbolize model spaces, adding a playful layer to technical concepts.
### Interpretation
The diagram represents a **knowledge graph-driven pipeline** for NLP model development. HuggingKG formalizes relationships between models, datasets, and tasks, enabling scalable fine-tuning (e.g., `medBERT` for biomedical tasks). HuggingBench operationalizes this knowledge by:
1. Recommending resources based on user preferences (`like?`).
2. Classifying tasks to match datasets (`define for`).
3. Tracing model evolution via fine-tuning (`fine-tune`).
The use of Sesame Street characters suggests an emphasis on **accessibility** and **modularity**, making complex workflows intuitive. The absence of numerical data implies the diagram prioritizes **conceptual relationships** over quantitative metrics.