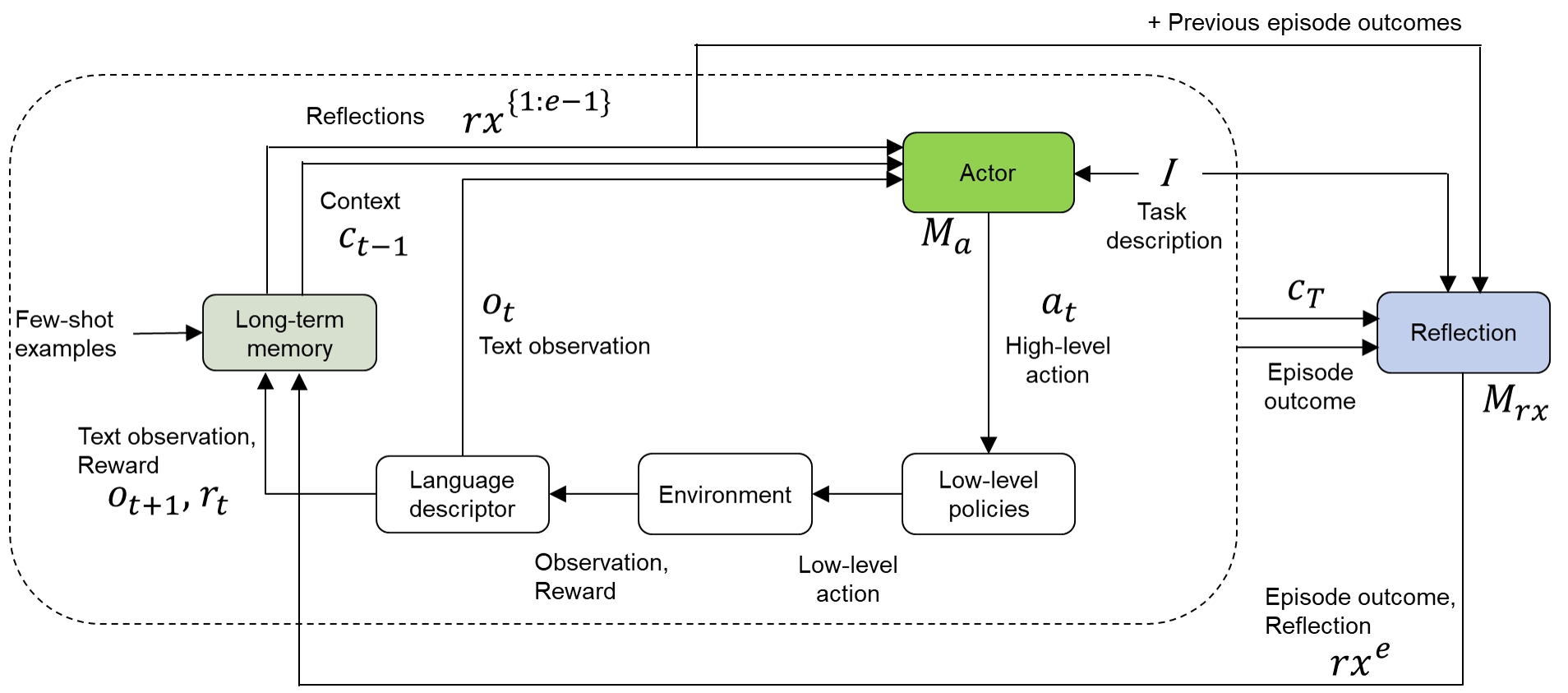
## System Diagram: Actor-Reflection Interaction
### Overview
The image is a system diagram illustrating the interaction between an "Actor" and a "Reflection" module within an environment. It depicts the flow of information, actions, and feedback loops between these components, including the environment, long-term memory, and low-level policies.
### Components/Axes
* **Nodes:**
* Actor (Green rounded rectangle)
* Reflection (Blue rounded rectangle)
* Long-term memory (Green rounded rectangle)
* Language descriptor (White rounded rectangle)
* Environment (White rounded rectangle)
* Low-level policies (White rounded rectangle)
* **Labels:**
* Reflections: rx^{1:e-1}
* Context: c_{t-1}
* Few-shot examples
* Text observation: o_t
* Text observation, Reward: o_{t+1}, r_t
* Observation, Reward
* Low-level action
* Task description: I
* High-level action: a_t
* Episode outcome: c_T
* Episode outcome, Reflection: rx^e
* M_a (below Actor)
* M_rx (below Reflection)
* + Previous episode outcomes (top-right)
### Detailed Analysis
* **Actor:** The Actor receives input from "Reflections rx^{1:e-1}", "Context c_{t-1}", and "Task description I". It outputs a "High-level action a_t" to "Low-level policies". The Actor has an associated memory M_a.
* **Reflection:** The Reflection module receives input from "Task description I", "Episode outcome c_T", and "+ Previous episode outcomes". It outputs to "Reflections rx^{1:e-1}", and "Long-term memory". The Reflection module has an associated memory M_rx, which also receives "Episode outcome, Reflection rx^e".
* **Long-term memory:** Receives "Few-shot examples" and "Text observation, Reward o_{t+1}, r_t". It outputs "Context c_{t-1}" and "Text observation o_t".
* **Language descriptor:** Receives "Text observation o_t" and outputs "Observation, Reward" to the "Environment".
* **Environment:** Receives "Observation, Reward" from the "Language descriptor" and "Low-level action" from "Low-level policies". It outputs "Text observation, Reward o_{t+1}, r_t" to "Long-term memory".
* **Low-level policies:** Receives "High-level action a_t" from the "Actor" and outputs "Low-level action" to the "Environment".
### Key Observations
* The diagram illustrates a closed-loop system where the Actor interacts with the Environment through high-level actions, which are then translated into low-level actions.
* The Reflection module plays a crucial role in learning and adaptation by processing episode outcomes and updating the long-term memory.
* The system incorporates both few-shot examples and continuous feedback (reward) to guide learning.
### Interpretation
The diagram represents a reinforcement learning architecture where an agent (Actor) learns to interact with an environment. The Reflection module allows the agent to learn from past experiences and improve its performance over time. The long-term memory stores relevant information that can be used to guide future actions. The inclusion of few-shot examples suggests a meta-learning approach, where the agent can quickly adapt to new tasks based on limited data. The overall architecture emphasizes the importance of both exploration (through interaction with the environment) and exploitation (through leveraging past experiences) in achieving optimal performance.