\n
## Diagram: Reflexion Architecture
### Overview
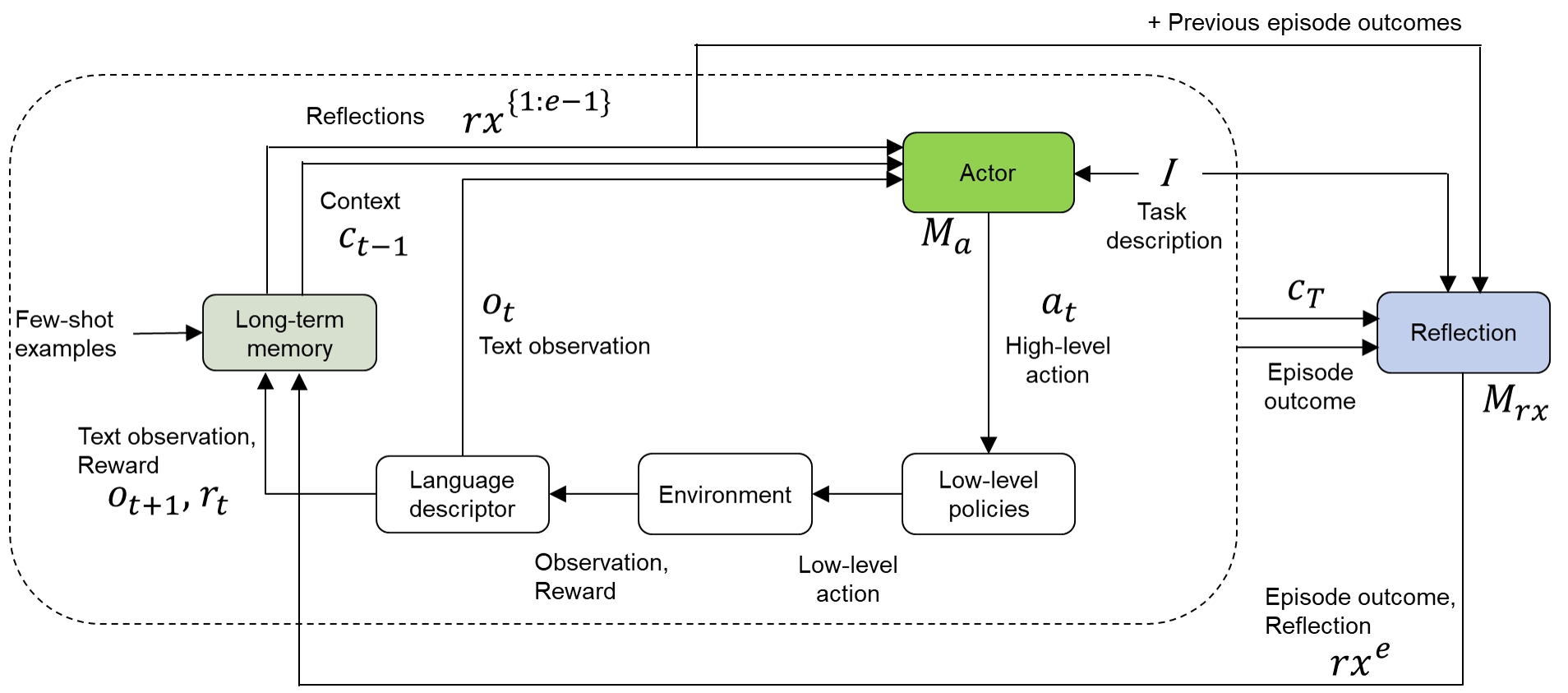
The image depicts a diagram of a Reflexion architecture, a reinforcement learning framework that incorporates reflection as a key component. The diagram illustrates the flow of information between different modules, including an Actor, Environment, Language descriptor, and Long-term memory. It shows how the system uses text observations, rewards, and reflections to learn and improve its performance over multiple episodes.
### Components/Axes
The diagram consists of several key components:
* **Actor:** Represented by a green rectangle labeled "Actor" with internal elements *I* (Task description) and *M<sub>a</sub>*. Outputs "a<sub>t</sub>" (High-level action).
* **Environment:** Represented by a light-blue rectangle labeled "Environment". Outputs "Observation, Reward".
* **Language descriptor:** Represented by a yellow rectangle labeled "Language descriptor".
* **Long-term memory:** Represented by a gray triangle labeled "Long-term memory".
* **Reflection:** Represented by a dark-blue rectangle labeled "Reflection" with internal elements *M<sub>rx</sub>*. Outputs "rx<sup>e</sup>" (Episode outcome, Reflection).
* **Context:** Represented by "c<sub>t-1</sub>".
* **Text observation:** Represented by "o<sub>t</sub>".
* **Text observation, Reward:** Represented by "o<sub>t+1</sub>, r<sub>t</sub>".
* **Reflections:** Represented by "r<sub>x</sub><sup>{1-e}</sup>".
* **Episode outcome:** Represented by "c<sub>T</sub>".
* **Low-level policies:** Outputs "Low-level action".
* **Few-shot examples:** Input to Long-term memory.
* **+ Previous episode outcomes:** Input to Actor.
Arrows indicate the direction of information flow between these components. Dotted arrows represent less direct or delayed information flow.
### Detailed Analysis or Content Details
The diagram illustrates a cyclical process.
1. **Initialization:** The system starts with "Few-shot examples" stored in "Long-term memory".
2. **Context & Observation:** The "Long-term memory" provides "Context" (c<sub>t-1</sub>) to the "Actor". The "Environment" provides a "Text observation" (o<sub>t</sub>).
3. **Action Selection:** The "Actor" uses the "Context" and "Task description" (*I*) to generate a "High-level action" (a<sub>t</sub>).
4. **Environment Interaction:** The "High-level action" is translated into a "Low-level action" by "Low-level policies" and sent to the "Environment". The "Environment" returns an "Observation" and "Reward".
5. **Language Description:** The "Language descriptor" processes the "Observation" and "Reward".
6. **Memory Update:** The "Text observation" (o<sub>t+1</sub>) and "Reward" (r<sub>t</sub>) are stored in the "Long-term memory".
7. **Reflection:** The "Episode outcome" (c<sub>T</sub>) and "Reflection" (M<sub>rx</sub>) are generated.
8. **Context Update:** The "Reflections" (r<sub>x</sub><sup>{1-e}</sup>) from previous episodes are fed back into the "Actor" along with the "Task description" (*I*).
9. **Iteration:** The process repeats for subsequent episodes.
### Key Observations
The diagram highlights the importance of reflection in the learning process. The "Reflection" module receives information about the "Episode outcome" and generates a "Reflection" that is used to update the "Actor's" context for future episodes. The "Long-term memory" serves as a repository of past experiences, providing context for the "Actor". The cyclical nature of the diagram emphasizes the iterative learning process.
### Interpretation
This diagram represents a sophisticated reinforcement learning architecture that aims to improve performance through self-reflection. The inclusion of a "Language descriptor" suggests that the system can process and understand natural language, potentially allowing it to learn from textual feedback or generate textual explanations of its actions. The "Long-term memory" enables the system to retain and utilize past experiences, preventing it from repeating mistakes and allowing it to build upon previous successes. The "Reflection" module is crucial for identifying areas for improvement and adapting the system's behavior accordingly. The diagram suggests a system capable of not just *doing* but also *understanding* and *learning from* its actions, a key step towards more intelligent and adaptable AI agents. The use of mathematical notation (e.g., r<sub>x</sub><sup>{1-e}</sup>) indicates a formal, model-based approach to reinforcement learning. The diagram is a high-level overview and does not provide details about the specific algorithms or implementations used within each module.