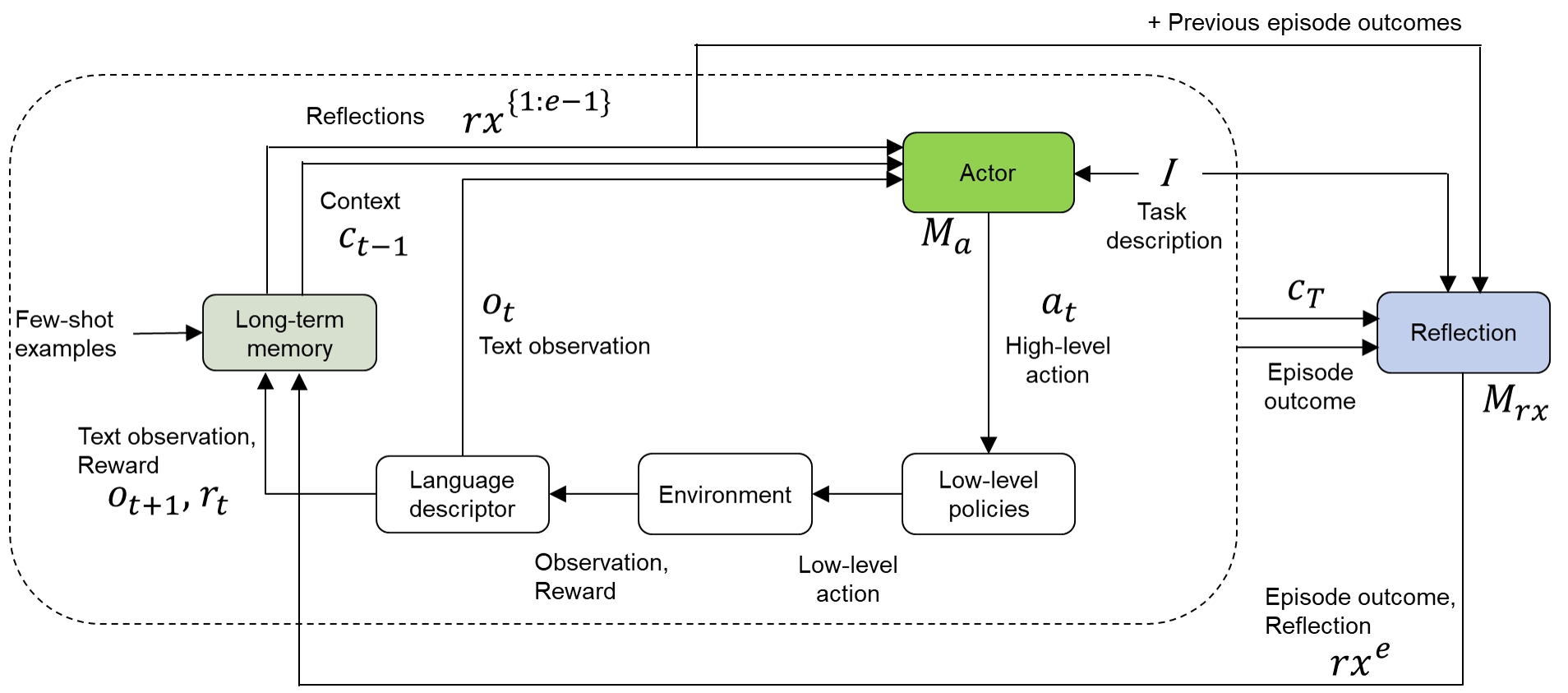
## Flowchart: Reinforcement Learning with Reflection and Long-Term Memory System
### Overview
The diagram illustrates a complex reinforcement learning (RL) system integrating long-term memory, reflection, and few-shot learning. It depicts interactions between components such as the Actor, Environment, Language Descriptor, and Reflection module, with feedback loops and memory retention mechanisms.
### Components/Axes
1. **Key Components**:
- **Long-term memory**: Stores contextual information (`C_{t-1}`) and few-shot examples.
- **Language descriptor**: Processes text observations (`O_t`) and rewards (`r_t`).
- **Environment**: Executes low-level actions based on observations and rewards.
- **Actor**: Generates high-level actions (`a_t`) using context and task descriptions.
- **Reflection**: Analyzes episode outcomes (`C_T`) and task descriptions to produce reflections (`r_x^e`).
- **Few-shot examples**: Provide initial task demonstrations.
2. **Flow Connections**:
- **Inputs**:
- Few-shot examples → Long-term memory.
- Text observation (`O_t`) and reward (`r_t`) → Language descriptor.
- Previous episode outcomes → Actor and Reflection.
- **Outputs**:
- Low-level actions → Environment.
- High-level actions (`a_t`) → Environment.
- Reflections (`r_x^e`) → System feedback.
3. **Memory and Context**:
- Context (`C_{t-1}`) is derived from long-term memory and updated iteratively.
- Reflections (`r_x^{1:e-1}`) aggregate past episode outcomes.
### Detailed Analysis
- **Long-term memory**: Retains `C_{t-1}` (context) and few-shot examples, enabling the system to leverage prior knowledge.
- **Language descriptor**: Converts raw text observations (`O_t`) and rewards (`r_t`) into structured inputs for the environment.
- **Environment**: Bridges high-level actions (`a_t`) and low-level policies, translating decisions into executable steps.
- **Actor**: Combines context (`C_{t-1}`), text observations (`O_t`), and previous outcomes to determine optimal high-level actions.
- **Reflection**: Uses episode outcomes (`C_T`) and task descriptions to refine future decisions via `r_x^e`.
### Key Observations
1. **Feedback Loops**:
- Reflections (`r_x^e`) and previous outcomes (`r_x^{1:e-1}`) feed back into the Actor and Reflection module, enabling meta-learning.
2. **Few-Shot Learning**:
- Initial examples guide the system’s initial behavior, reducing reliance on extensive training data.
3. **Hierarchical Decision-Making**:
- The Actor operates at a high level, while the Environment handles low-level execution, creating a modular architecture.
### Interpretation
This system combines **reinforcement learning** with **few-shot learning** and **reflection** to enhance adaptability. The Actor’s decisions are informed by both immediate rewards and long-term context, while the Reflection module enables continuous improvement by analyzing past episodes. The integration of few-shot examples suggests the system can generalize from minimal demonstrations, making it efficient for complex tasks with limited data. The feedback loops ensure that the system evolves dynamically, balancing exploration (via the Environment) and exploitation (via the Actor and Reflection).