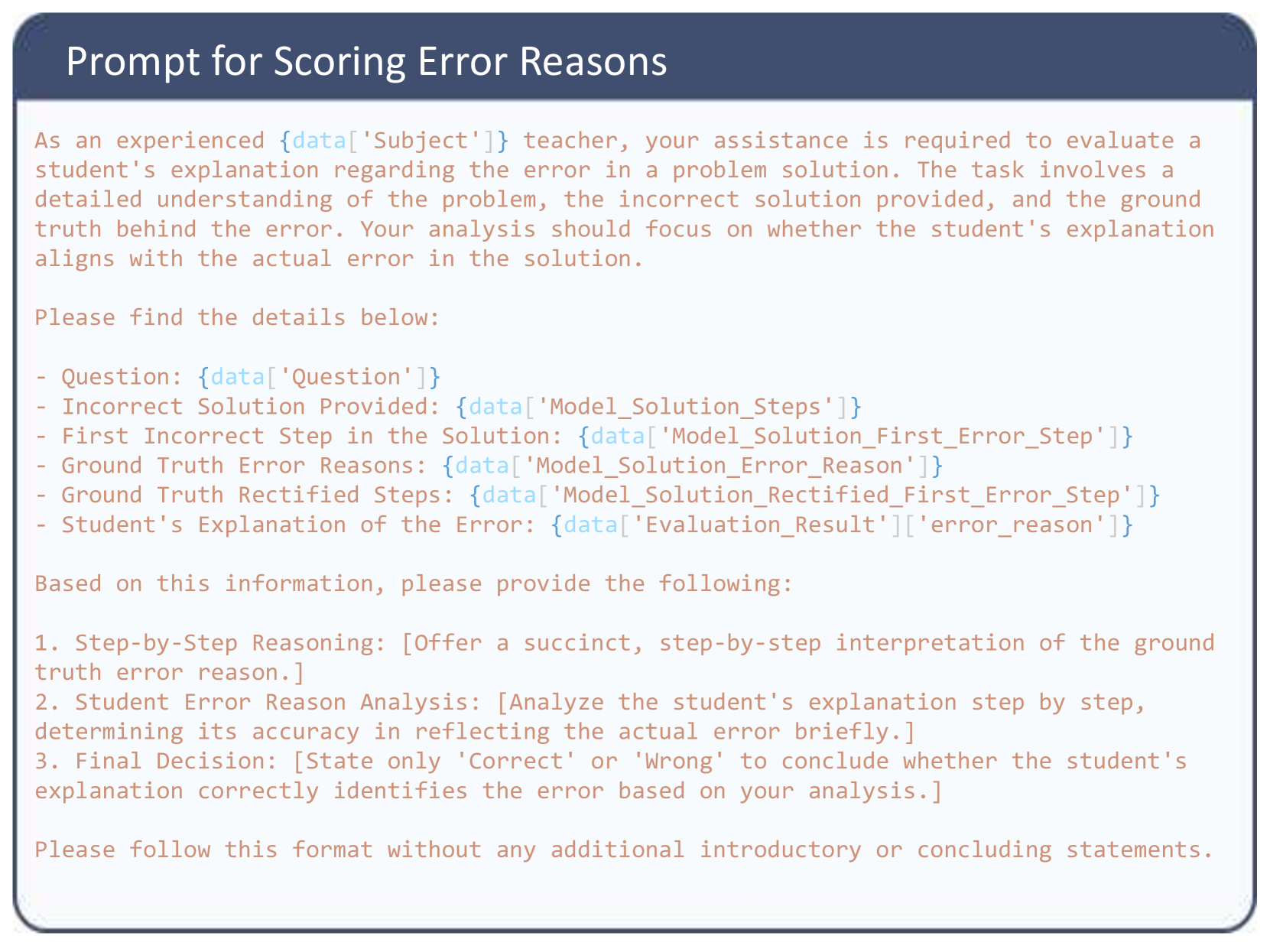
## Text Block / Prompt Template: Prompt for Scoring Error Reasons
### Overview
The image displays a presentation slide or a screenshot of a text block containing a structured prompt template. This template is designed to be fed into a Large Language Model (LLM) to act as an automated evaluator (LLM-as-a-judge). The prompt instructs the AI to adopt the persona of a teacher to evaluate whether a student correctly identified the reason for an error in a given problem's solution.
### Components
The image is visually divided into two main spatial regions:
1. **Header (Top):** A dark blue rectangular banner spanning the width of the image, containing white, sans-serif text.
2. **Main Body (Center to Bottom):** A white rectangular area with a light blue/grey rounded border. It contains the body of the prompt written in a monospaced, typewriter-style font colored in a light reddish-brown/salmon hue.
The text itself contains **Variables** formatted in a syntax resembling Python dictionary or JSON data extraction (e.g., `{data['Key']}`).
### Content Details
Here is the precise transcription of the text within the image, maintaining the original formatting and variable placeholders:
**[Header Text]**
Prompt for Scoring Error Reasons
**[Main Body Text]**
As an experienced `{data['Subject']}` teacher, your assistance is required to evaluate a student's explanation regarding the error in a problem solution. The task involves a detailed understanding of the problem, the incorrect solution provided, and the ground truth behind the error. Your analysis should focus on whether the student's explanation aligns with the actual error in the solution.
Please find the details below:
- Question: `{data['Question']}`
- Incorrect Solution Provided: `{data['Model_Solution_Steps']}`
- First Incorrect Step in the Solution: `{data['Model_Solution_First_Error_Step']}`
- Ground Truth Error Reasons: `{data['Model_Solution_Error_Reason']}`
- Ground Truth Rectified Steps: `{data['Model_Solution_Rectified_First_Error_Step']}`
- Student's Explanation of the Error: `{data['Evaluation_Result']['error_reason']}`
Based on this information, please provide the following:
1. Step-by-Step Reasoning: [Offer a succinct, step-by-step interpretation of the ground truth error reason.]
2. Student Error Reason Analysis: [Analyze the student's explanation step by step, determining its accuracy in reflecting the actual error briefly.]
3. Final Decision: [State only 'Correct' or 'Wrong' to conclude whether the student's explanation correctly identifies the error based on your analysis.]
Please follow this format without any additional introductory or concluding statements.
### Key Observations
* **Dynamic Data Injection:** The prompt relies heavily on dynamic variables (indicated by `{data[...]}`). This proves the text is a template used in an automated pipeline, likely a Python script iterating over a dataset of student answers.
* **Persona Adoption:** The prompt begins by assigning a role ("experienced `{data['Subject']}` teacher") to set the context and tone for the AI's evaluation.
* **Chain-of-Thought Prompting:** The requested output format (Steps 1, 2, and 3) forces the model to explain its reasoning *before* arriving at a final decision. This is a well-known prompt engineering technique to increase the accuracy of LLM outputs.
* **Strict Output Constraints:** The final sentence explicitly forbids "introductory or concluding statements" (often referred to as "chatty" behavior in LLMs), ensuring the output can be easily parsed by a computer program looking for the specific numbered list and the binary 'Correct'/'Wrong' string.
### Interpretation
This image reveals the backend methodology of an automated educational assessment system.
**What the data suggests:** The creators of this system are using an AI to grade students, but rather than asking the AI to solve the math/logic problem from scratch, they are providing the AI with the "Ground Truth" (the correct answer and the exact reason for the error). The AI's *only* job is to compare the student's written explanation against this provided ground truth.
**Reading between the lines (Peircean investigative):**
1. The variable naming convention (`Model_Solution_Steps`, `Model_Solution_First_Error_Step`) strongly implies that the "Incorrect Solution" being evaluated was actually generated by an AI model initially, and the "Student" is likely evaluating the AI's mistake. This suggests a workflow related to Reinforcement Learning from Human Feedback (RLHF) or a platform where students learn by critiquing AI-generated errors.
2. The nested variable `{data['Evaluation_Result']['error_reason']}` suggests a complex data structure (like a nested JSON object) is being passed into the prompt formatting engine.
3. The strict formatting request at the end is a defensive measure against LLM "hallucinations" or formatting inconsistencies, which would break the regular expressions (Regex) or parsing scripts used to extract the final 'Correct' or 'Wrong' grade into a database.