\n
## Diagram: Neural Network Training Strategies
### Overview
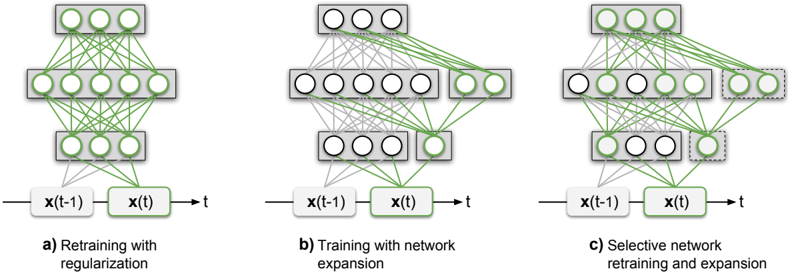
The image presents a comparative diagram illustrating three different strategies for training neural networks over time. Each strategy is represented by a separate neural network diagram, labeled (a), (b), and (c). All diagrams depict a recurrent neural network structure with input `x(t-1)` at time `t-1` and output `x(t)` at time `t`. The diagrams visually demonstrate how the network connections and structure change during retraining and expansion.
### Components/Axes
Each diagram consists of the following components:
* **Input Layer:** Represented by `x(t-1)` on the left.
* **Hidden Layers:** Multiple layers of interconnected nodes. The number of nodes in each layer varies between the diagrams.
* **Output Layer:** Represented by `x(t)` on the right.
* **Connections:** Green lines connecting nodes between layers, representing the flow of information.
* **Labels:** Each diagram is labeled with a descriptive title:
* (a) Retraining with regularization
* (b) Training with network expansion
* (c) Selective network retraining and expansion
### Detailed Analysis or Content Details
**Diagram (a): Retraining with Regularization**
* The network has three layers: an input layer, a hidden layer with approximately 8 nodes, and an output layer with approximately 4 nodes.
* All nodes in the hidden layer are connected to both the input and output layers.
* The connections appear to remain constant throughout the retraining process, suggesting that the network's structure is not changing, but the weights are being adjusted (regularization).
**Diagram (b): Training with Network Expansion**
* The network has three layers: an input layer, two hidden layers (approximately 8 nodes each), and an output layer with approximately 4 nodes.
* The first hidden layer is fully connected to the input layer, and the second hidden layer is fully connected to the first hidden layer. The output layer is connected to the second hidden layer.
* The network expands by adding nodes to the hidden layers during training.
**Diagram (c): Selective Network Retraining and Expansion**
* The network has three layers: an input layer, two hidden layers (approximately 8 nodes each), and an output layer with approximately 4 nodes.
* The connections are more complex than in diagrams (a) and (b). Some nodes in the hidden layers are connected to the input and output layers, while others are only connected to the adjacent layers.
* The network selectively retrains and expands by adding or modifying connections between nodes. Some nodes are highlighted with a lighter shade of green, indicating they are being retrained or expanded.
### Key Observations
* Diagram (a) shows a static network structure, implying weight adjustments without structural changes.
* Diagram (b) demonstrates a network growing in size by adding layers and nodes.
* Diagram (c) illustrates a more nuanced approach, where the network adapts by selectively retraining and expanding specific connections and nodes.
* The input `x(t-1)` and output `x(t)` are consistent across all three diagrams, indicating that the input and output remain the same while the training strategy varies.
### Interpretation
The diagram illustrates three different approaches to training recurrent neural networks for time-series data.
* **Retraining with regularization (a)** is a common technique to prevent overfitting by penalizing complex models. It maintains the network's structure while adjusting its weights.
* **Training with network expansion (b)** allows the network to increase its capacity as it learns, potentially capturing more complex patterns in the data.
* **Selective network retraining and expansion (c)** offers a more flexible approach, where the network can adapt its structure and connections based on the specific needs of the task. This approach can be more efficient than expanding the entire network, as it focuses on the most relevant parts.
The diagrams suggest a progression in complexity and adaptability. Regularization is the simplest approach, while selective retraining and expansion is the most sophisticated. The choice of strategy depends on the specific characteristics of the data and the desired level of performance. The use of `x(t-1)` and `x(t)` indicates that these are recurrent networks, designed to process sequential data where the output at time `t` depends on the input at time `t-1`.