\n
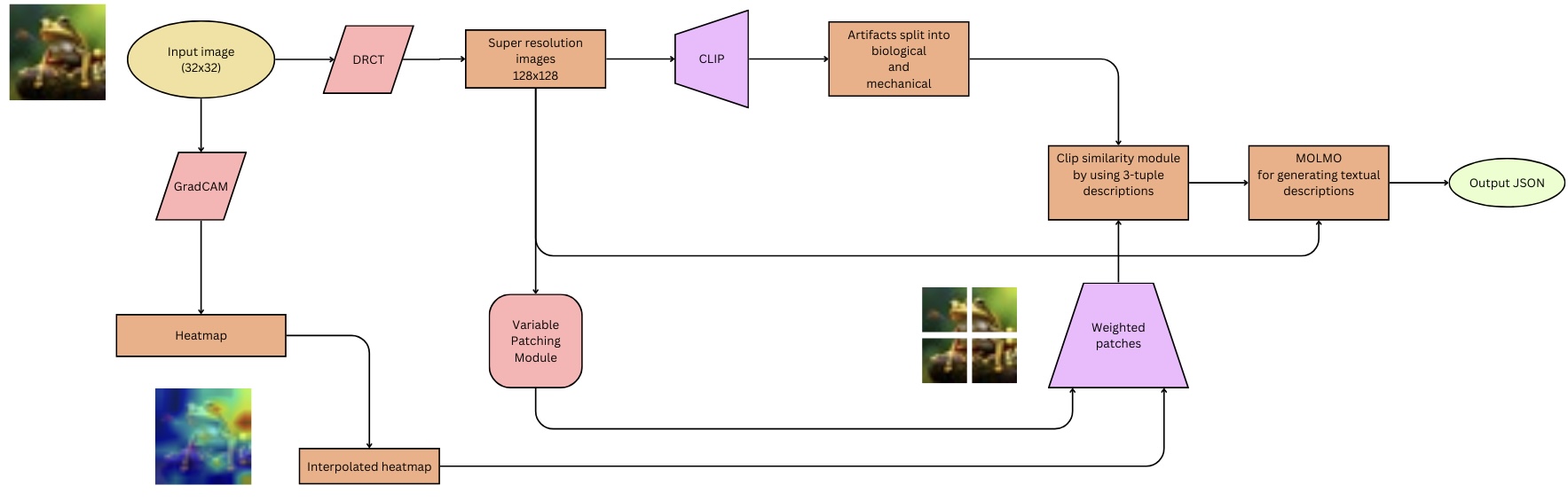
## Diagram: Artifact Analysis Pipeline
### Overview
This diagram illustrates a pipeline for analyzing artifacts, starting with an input image and culminating in a JSON output. The pipeline involves image processing, artifact segmentation, and textual description generation. The process appears to be designed for archaeological or historical artifact analysis, leveraging computer vision and natural language processing techniques.
### Components/Axes
The diagram consists of several processing blocks connected by arrows indicating the flow of data. Key components include:
* **Input image (32x32):** The initial input to the pipeline.
* **DRCT:** A processing step following the input image.
* **Super resolution images 128x128:** An image upscaling step.
* **CLIP:** A component likely related to Contrastive Language-Image Pre-training.
* **Artifacts split into biological and mechanical:** A segmentation step categorizing artifacts.
* **Clip similarity module by using 3-tuple descriptions:** A module for comparing artifacts using CLIP embeddings.
* **MOLMO for generating textual descriptions:** A module for generating textual descriptions of the artifacts.
* **Output .JSON:** The final output of the pipeline.
* **GradCAM:** A visualization technique for understanding which parts of the image contribute to the model's decision.
* **Heatmap:** A visual representation of the GradCAM output.
* **Variable Patching Module:** A module for dividing the image into variable-sized patches.
* **Interpolated heatmap:** A processed heatmap.
* **Weighted patches:** Patches assigned weights based on the heatmap.
### Detailed Analysis or Content Details
The pipeline flows as follows:
1. An **Input image (32x32)** is fed into the **DRCT** module.
2. The output of **DRCT** is passed to a **Super resolution images 128x128** module, increasing the image resolution.
3. The upscaled image is then processed by **CLIP**.
4. **CLIP**'s output is used to **Artifacts split into biological and mechanical** categories.
5. The categorized artifacts are then processed by a **Clip similarity module by using 3-tuple descriptions**.
6. The output of the similarity module is fed into **MOLMO for generating textual descriptions**.
7. Finally, **MOLMO** generates a **Output .JSON** file.
A parallel branch starts with the **Input image (32x32)**:
1. It is processed by **GradCAM**.
2. **GradCAM** generates a **Heatmap**.
3. The **Heatmap** is processed by a **Variable Patching Module**.
4. The output of the patching module is an **Interpolated heatmap**.
5. The **Interpolated heatmap** is used to generate **Weighted patches**.
6. The **Weighted patches** are then fed into the **Clip similarity module by using 3-tuple descriptions**.
### Key Observations
The pipeline utilizes both a primary path for artifact analysis and a parallel path for generating heatmaps and weighted patches, which are then integrated into the main analysis stream. The use of CLIP suggests a focus on semantic understanding of the artifacts. The final JSON output indicates a structured representation of the analysis results. The initial image resolution is very low (32x32), suggesting the DRCT and Super Resolution modules are crucial for improving the quality of the input data.
### Interpretation
This diagram represents a sophisticated system for automated artifact analysis. The pipeline combines image processing techniques (DRCT, super-resolution, GradCAM, variable patching) with semantic understanding (CLIP, MOLMO) to generate structured textual descriptions of artifacts. The separation of artifacts into "biological" and "mechanical" categories suggests the system is designed to handle a diverse range of artifact types. The integration of heatmap-based weighting indicates an attempt to focus the analysis on the most salient features of the artifacts. The final JSON output allows for easy integration of the analysis results into other systems or databases. The pipeline appears to be designed for automated archaeological or historical research, potentially enabling large-scale analysis of artifact collections.