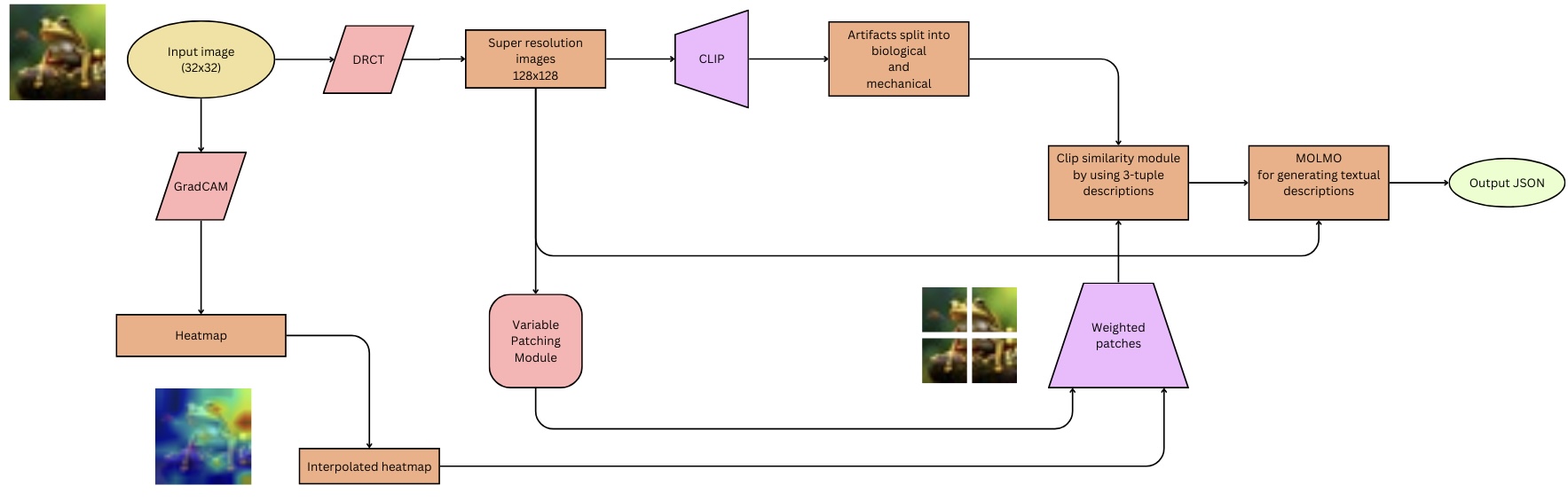
## Flowchart: Multimodal Image Analysis Pipeline
### Overview
The diagram illustrates a technical pipeline for analyzing input images through a combination of computer vision and natural language processing (NLP) techniques. The process begins with a 32x32 input image and culminates in a JSON output containing textual descriptions. Key components include GradCAM heatmaps, CLIP-based artifact classification, and MOLMO-driven text generation.
### Components/Axes
1. **Input Image**: 32x32 pixel resolution (top-left corner).
2. **GradCAM**: Generates a heatmap from the input image (left-center).
3. **Heatmap**: Visual representation of GradCAM output (bottom-left).
4. **Interpolated Heatmap**: Enhanced resolution version of the heatmap (bottom-center).
5. **Super-Resolution Images**: 128x128 upscaled images (center-left).
6. **CLIP**: Processes super-resolution images to split artifacts into biological and mechanical categories (center).
7. **Clip Similarity Module**: Uses 3-tuple descriptions from CLIP (center-right).
8. **MOLMO**: Generates textual descriptions (right-center).
9. **Output JSON**: Final structured output (top-right).
### Detailed Analysis
- **Input Image**: A 32x32 pixel image of a frog (top-left).
- **GradCAM**: Produces a heatmap highlighting biologically relevant regions (left-center).
- **Heatmap**: Color-coded visualization (blue to red) of GradCAM output (bottom-left).
- **Interpolated Heatmap**: Smoother version of the heatmap (bottom-center).
- **Super-Resolution Images**: 128x128 images derived from the input (center-left).
- **CLIP**: Classifies artifacts into biological (e.g., frog) and mechanical (e.g., background) categories (center).
- **Clip Similarity Module**: Compares descriptions using 3-tuple embeddings (center-right).
- **MOLMO**: Text generation module producing descriptions like "A frog sitting on a leaf" (right-center).
- **Output JSON**: Structured data containing descriptions and classifications (top-right).
### Key Observations
1. **Multimodal Integration**: The pipeline combines visual (GradCAM, heatmaps) and textual (CLIP, MOLMO) modalities.
2. **Resolution Scaling**: Input images are upscaled from 32x32 to 128x128 for detailed analysis.
3. **Artifact Differentiation**: CLIP explicitly separates biological and mechanical elements.
4. **Weighted Patches**: The variable patching module combines interpolated heatmaps with weighted regions for refined analysis.
### Interpretation
This pipeline demonstrates a hybrid approach to image analysis, leveraging GradCAM for attention mapping and CLIP/MOLMO for semantic understanding. The variable patching module acts as a bridge between visual saliency and textual generation, enabling context-aware descriptions. The final JSON output likely serves applications requiring structured data, such as medical imaging analysis or automated object recognition. The use of 3-tuple descriptions in the clip similarity module suggests a focus on precise semantic relationships between visual and textual elements.