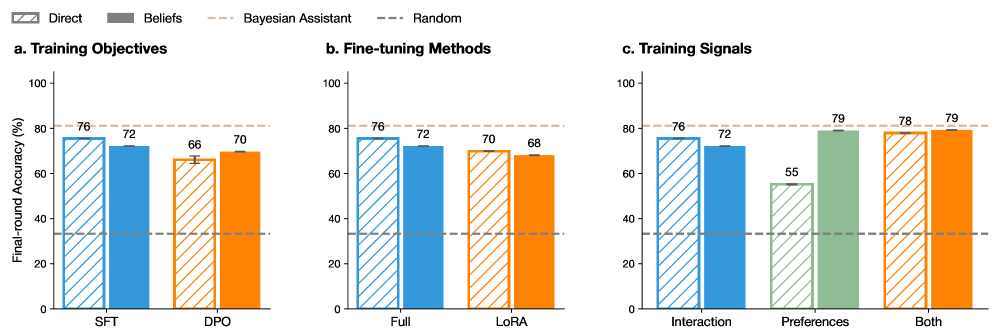
\n
## Bar Charts: Accuracy Comparison of Language Model Training Techniques
### Overview
The image presents three bar charts (labeled a, b, and c) comparing the final-round accuracy (%) of a language model under different training conditions. Each chart focuses on a different aspect of the training process: training objectives, fine-tuning methods, and training signals. Error bars are present on some bars, indicating variance.
### Components/Axes
* **Y-axis (all charts):** "Final-round Accuracy (%)", ranging from 0 to 100.
* **X-axis:** Varies depending on the chart.
* **Chart a (Training Objectives):** "SFT", "DPO"
* **Chart b (Fine-tuning Methods):** "Full", "LoRA"
* **Chart c (Training Signals):** "Interaction", "Preferences", "Both"
* **Legend (top-left, applies to all charts):**
* "Direct" (Solid Blue)
* "Beliefs" (Striped Blue)
* "Bayesian Assistant" (Solid Orange)
* "Random" (Striped Green)
### Detailed Analysis or Content Details
**Chart a: Training Objectives**
* **Direct (SFT):** Approximately 76% accuracy.
* **Beliefs (SFT):** Approximately 72% accuracy.
* **Direct (DPO):** Approximately 66% accuracy.
* **Beliefs (DPO):** Approximately 70% accuracy.
* The "Direct" bars are consistently higher than the "Beliefs" bars for both SFT and DPO.
* Error bars are present on the "Direct" DPO bar, indicating some variance.
**Chart b: Fine-tuning Methods**
* **Direct (Full):** Approximately 76% accuracy.
* **Beliefs (Full):** Approximately 72% accuracy.
* **Direct (LoRA):** Approximately 70% accuracy.
* **Beliefs (LoRA):** Approximately 68% accuracy.
* Similar to Chart a, "Direct" consistently outperforms "Beliefs" for both "Full" and "LoRA".
**Chart c: Training Signals**
* **Direct (Interaction):** Approximately 76% accuracy.
* **Beliefs (Interaction):** Approximately 72% accuracy.
* **Direct (Preferences):** Approximately 55% accuracy.
* **Beliefs (Preferences):** Approximately 79% accuracy.
* **Direct (Both):** Approximately 78% accuracy.
* **Beliefs (Both):** Approximately 79% accuracy.
* In this chart, "Beliefs" outperforms "Direct" for "Preferences" and "Both". "Direct" is higher for "Interaction".
### Key Observations
* The "Direct" approach generally yields higher accuracy than the "Beliefs" approach, except when using "Preferences" or "Both" training signals.
* The "Interaction" training signal results in the highest accuracy for the "Direct" approach.
* The "Preferences" training signal results in significantly lower accuracy for the "Direct" approach, but comparable or higher accuracy for the "Beliefs" approach.
* The "Random" data series is only present in Chart c, and shows a consistent accuracy of approximately 79% for "Both" training signals.
### Interpretation
The data suggests that the "Direct" training approach is more effective when using "Interaction" or "Full" fine-tuning methods. However, the "Beliefs" approach appears to be more robust or even superior when utilizing "Preferences" or a combination of "Both" training signals. This could indicate that the "Beliefs" approach is better at leveraging information from preference-based feedback, while the "Direct" approach benefits more from direct interaction data. The lower accuracy of the "Direct" approach with "Preferences" might suggest that it struggles to generalize from preference signals without additional context or regularization. The consistent performance of the "Random" approach at a high level suggests that the training signals themselves are strong predictors of accuracy, regardless of the specific method used. The error bars on the "Direct" DPO bar in Chart a indicate that the results for that condition may be less reliable or have higher variability.