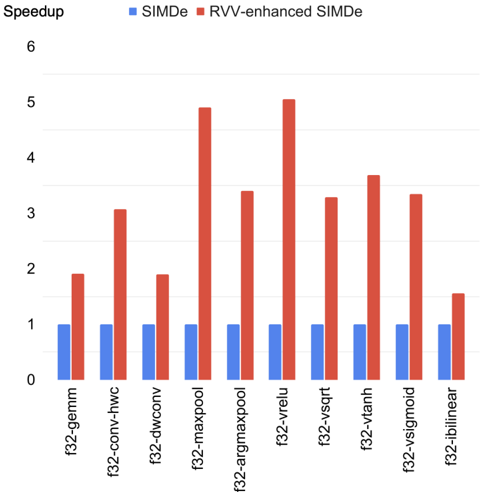
## Bar Chart: Speedup Comparison of SIMDe vs. RVV-enhanced SIMDe
### Overview
The image is a bar chart comparing the speedup achieved by SIMDe (Single Instruction, Multiple Data emulation) and RVV-enhanced SIMDe (RISC-V Vector extension enhanced SIMDe) across various floating-point operations. The x-axis represents different operations, and the y-axis represents the speedup factor.
### Components/Axes
* **Title:** Speedup
* **Y-axis:** Speedup, ranging from 0 to 6 in increments of 1.
* **X-axis:** Categorical axis representing different floating-point operations:
* f32-gemm
* f32-conv-hwc
* f32-dwconv
* f32-maxpool
* f32-argmaxpool
* f32-vrelu
* f32-vsqrt
* f32-vtanh
* f32-vsigmoid
* f32-ibilinear
* **Legend:** Located at the top of the chart.
* Blue: SIMDe
* Red: RVV-enhanced SIMDe
### Detailed Analysis
The chart compares the speedup of SIMDe (blue bars) and RVV-enhanced SIMDe (red bars) for different operations. SIMDe generally shows a speedup of approximately 1 across all operations. RVV-enhanced SIMDe shows significantly higher speedups, varying depending on the operation.
Here's a breakdown of the approximate speedup values for each operation:
* **f32-gemm:**
* SIMDe: ~1
* RVV-enhanced SIMDe: ~1.9
* **f32-conv-hwc:**
* SIMDe: ~1
* RVV-enhanced SIMDe: ~3.1
* **f32-dwconv:**
* SIMDe: ~1
* RVV-enhanced SIMDe: ~1.9
* **f32-maxpool:**
* SIMDe: ~1
* RVV-enhanced SIMDe: ~4.9
* **f32-argmaxpool:**
* SIMDe: ~1
* RVV-enhanced SIMDe: ~1
* **f32-vrelu:**
* SIMDe: ~1
* RVV-enhanced SIMDe: ~5.0
* **f32-vsqrt:**
* SIMDe: ~1
* RVV-enhanced SIMDe: ~3.3
* **f32-vtanh:**
* SIMDe: ~1
* RVV-enhanced SIMDe: ~3.7
* **f32-vsigmoid:**
* SIMDe: ~1
* RVV-enhanced SIMDe: ~3.4
* **f32-ibilinear:**
* SIMDe: ~1
* RVV-enhanced SIMDe: ~1.5
### Key Observations
* SIMDe consistently shows a speedup of approximately 1 across all operations.
* RVV-enhanced SIMDe provides significantly higher speedups compared to SIMDe for most operations.
* The highest speedups for RVV-enhanced SIMDe are observed in 'f32-maxpool' and 'f32-vrelu'.
* The lowest speedup for RVV-enhanced SIMDe is observed in 'f32-argmaxpool', where it is approximately equal to SIMDe.
### Interpretation
The data suggests that RVV-enhanced SIMDe offers substantial performance improvements over standard SIMDe for a variety of floating-point operations. The magnitude of the improvement varies depending on the specific operation, with 'f32-maxpool' and 'f32-vrelu' benefiting the most from the RVV enhancements. The 'f32-argmaxpool' operation shows little to no improvement with RVV-enhanced SIMDe, indicating that this particular operation may not be effectively vectorized or optimized by the RVV extensions. The consistent speedup of 1 for SIMDe across all operations likely indicates a baseline performance or the absence of significant optimization for these specific operations in the standard SIMDe implementation.