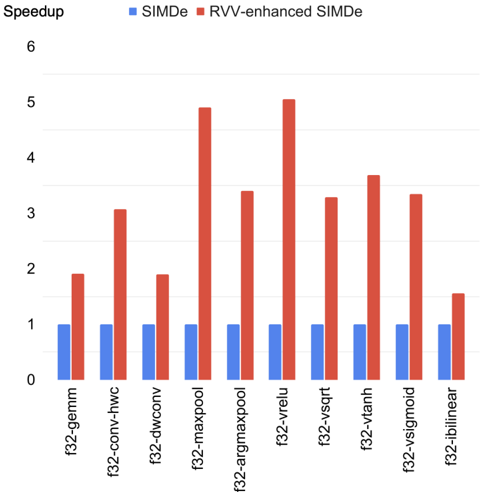
## Bar Chart: Speedup Comparison of SIMDe vs. RVV-enhanced SIMDe
### Overview
This is a vertical bar chart comparing the computational speedup achieved by two implementations across ten different floating-point (f32) operations. The chart demonstrates the performance improvement of an "RVV-enhanced SIMDe" implementation over a baseline "SIMDe" implementation.
### Components/Axes
* **Chart Title:** "Speedup" (located at the top-left).
* **Legend:** Positioned at the top-center. It defines two data series:
* **SIMDe:** Represented by blue bars.
* **RVV-enhanced SIMDe:** Represented by red bars.
* **Y-Axis (Vertical):** Represents the speedup multiplier. It is labeled with numerical markers: 0, 1, 2, 3, 4, 5, 6. The axis line is on the left.
* **X-Axis (Horizontal):** Lists ten distinct computational operations. The labels are rotated vertically for readability. From left to right, they are:
1. `f32-gemm`
2. `f32-conv-hwc`
3. `f32-dwconv`
4. `f32-maxpool`
5. `f32-argmaxpool`
6. `f32-vrelu`
7. `f32-vsqrt`
8. `f32-vtanh`
9. `f32-vsigmoid`
10. `f32-bilinear`
### Detailed Analysis
The chart presents paired bars for each operation. The blue "SIMDe" bars serve as the baseline, all normalized to a speedup value of approximately 1.0. The red "RVV-enhanced SIMDe" bars show the relative performance gain.
**Trend Verification:** For every single operation, the red bar is taller than its corresponding blue bar, indicating a consistent positive speedup from the RVV enhancement. The magnitude of this speedup varies significantly across operations.
**Data Point Extraction (Approximate Values):**
| Operation (X-Axis) | SIMDe (Blue) Speedup | RVV-enhanced SIMDe (Red) Speedup | Visual Trend & Notes |
| :--- | :--- | :--- | :--- |
| `f32-gemm` | ~1.0 | ~1.9 | Red bar is slightly below the 2.0 line. |
| `f32-conv-hwc` | ~1.0 | ~3.1 | Red bar is just above the 3.0 line. |
| `f32-dwconv` | ~1.0 | ~1.9 | Similar height to `f32-gemm` red bar. |
| `f32-maxpool` | ~1.0 | ~4.9 | Red bar is just below the 5.0 line. One of the highest gains. |
| `f32-argmaxpool` | ~1.0 | ~3.4 | Red bar is between 3.0 and 4.0, closer to 3.5. |
| `f32-vrelu` | ~1.0 | ~5.0 | Red bar touches the 5.0 line. This is the highest observed speedup. |
| `f32-vsqrt` | ~1.0 | ~3.3 | Red bar is slightly above the 3.0 line. |
| `f32-vtanh` | ~1.0 | ~3.7 | Red bar is between 3.0 and 4.0, closer to 4.0. |
| `f32-vsigmoid` | ~1.0 | ~3.4 | Similar height to `f32-argmaxpool` red bar. |
| `f32-bilinear` | ~1.0 | ~1.5 | The lowest speedup among the red bars, sitting midway between 1 and 2. |
### Key Observations
1. **Universal Improvement:** The RVV-enhanced version provides a speedup for all tested operations, with no performance regressions shown.
2. **High Variance in Gains:** The speedup factor ranges from a modest ~1.5x (`f32-bilinear`) to a substantial ~5.0x (`f32-vrelu`).
3. **Peak Performance:** The operations `f32-vrelu` and `f32-maxpool` show the most dramatic improvements, both reaching or nearing a 5x speedup.
4. **Baseline Consistency:** The SIMDe implementation's performance is perfectly flat across all operations (all at ~1.0), confirming it is the normalized baseline for this comparison.
### Interpretation
This chart provides strong evidence that integrating RVV (RISC-V Vector Extension) enhancements into the SIMDe library yields significant performance benefits for a variety of common floating-point computational kernels, particularly in the domain of neural network or signal processing operations (as suggested by names like `gemm`, `conv`, `maxpool`, `vtanh`).
The data suggests that the RVV enhancements are not uniformly effective. The operations showing the highest speedups (`vrelu`, `maxpool`) are likely those that benefit most from vectorization—operations with high data parallelism and simple, repetitive memory access patterns. Conversely, the more modest gain for `bilinear` might indicate a more complex computation pattern that is less amenable to the specific vector optimizations applied, or that the baseline implementation was already relatively efficient.
From a technical investment perspective, this analysis would guide a developer to prioritize using the RVV-enhanced SIMDe for workloads heavy in `vrelu`, `maxpool`, and `gemm` operations to maximize performance. The consistent, positive results across the board validate the enhancement strategy, while the variance highlights the importance of operation-specific profiling.