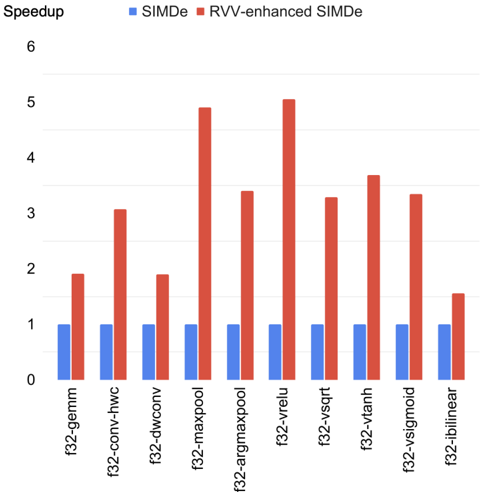
## Bar Chart: Speedup Comparison Between SIMDe and RVV-enhanced SIMDe
### Overview
The chart compares the speedup performance of two computational methods (SIMDe and RVV-enhanced SIMDe) across 10 different algorithms. Speedup values are measured on a logarithmic scale, with SIMDe represented by blue bars and RVV-enhanced SIMDe by red bars.
### Components/Axes
- **X-axis (Algorithms)**:
- f32-gemm
- f32-conv-hwc
- f32-dwconv
- f32-maxpool
- f32-argmaxpool
- f32-vrelu
- f32-vsqr
- f32-vtanh
- f32-vsigmoid
- f32-iblinear
- **Y-axis (Speedup)**: Logarithmic scale from 0 to 6
- **Legend**:
- Blue = SIMDe
- Red = RVV-enhanced SIMDe
- **Positioning**:
- Legend: Top-center
- X-axis labels: Bottom, centered below bars
- Y-axis: Left, vertical
### Detailed Analysis
| Algorithm | SIMDe (Blue) | RVV-enhanced SIMDe (Red) |
|--------------------|--------------|--------------------------|
| f32-gemm | ~1.0 | ~2.0 |
| f32-conv-hwc | ~1.0 | ~3.0 |
| f32-dwconv | ~1.0 | ~2.0 |
| f32-maxpool | ~1.0 | ~5.0 |
| f32-argmaxpool | ~1.0 | ~3.5 |
| f32-vrelu | ~1.0 | ~5.2 |
| f32-vsqr | ~1.0 | ~3.3 |
| f32-vtanh | ~1.0 | ~3.7 |
| f32-vsigmoid | ~1.0 | ~3.4 |
| f32-iblinear | ~1.0 | ~1.5 |
### Key Observations
1. **General Trend**: RVV-enhanced SIMDe consistently outperforms baseline SIMDe across all algorithms.
2. **Highest Gains**:
- f32-maxpool (5.0x speedup)
- f32-vrelu (5.2x speedup)
3. **Lowest Gains**:
- f32-iblinear (1.5x speedup for RVV-enhanced)
4. **Anomaly**: f32-iblinear shows significantly lower performance improvement compared to other algorithms.
### Interpretation
The data demonstrates that RVV-enhanced SIMDe provides substantial performance improvements (2-5x speedup) across most computational kernels, with the most significant gains observed in pooling operations (maxpool and argmaxpool) and activation functions (vrelu, vsigmoid). The f32-iblinear algorithm's minimal improvement (1.5x) suggests potential architectural limitations or implementation challenges for this specific operation. The consistent logarithmic scale indicates exponential performance benefits in certain workloads, highlighting the effectiveness of RVV optimizations for tensor operations in this benchmark suite.