\n
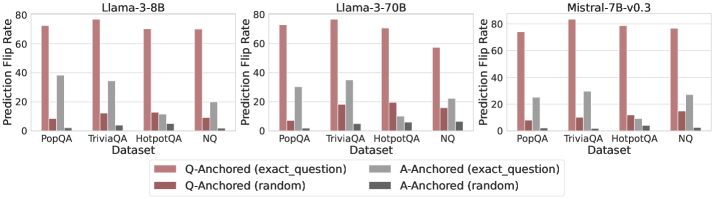
## Bar Chart: Prediction Flip Rate by Model and Dataset
### Overview
The image presents a comparative bar chart showing the "Prediction Flip Rate" across three different language models (Llama-3-8B, Llama-3-70B, and Mistral-7B-v0.3) and four datasets (PopQA, TriviaQA, HotpotQA, and NQ). The flip rate is measured for two anchoring methods: "Q-Anchored" (based on the exact question) and "A-Anchored" (based on the exact answer), each with both "exact question" and "random" variations.
### Components/Axes
* **X-axis:** "Dataset" with categories: PopQA, TriviaQA, HotpotQA, NQ.
* **Y-axis:** "Prediction Flip Rate" ranging from 0 to 80 (approximate).
* **Models (Columns):** Three separate charts, one for each model: Llama-3-8B, Llama-3-70B, Mistral-7B-v0.3. Each model's chart has the same x-axis.
* **Legend (Bottom-Center):**
* Q-Anchored (exact question) - Light Red
* A-Anchored (exact question) - Light Gray
* Q-Anchored (random) - Dark Red
* A-Anchored (random) - Dark Gray
### Detailed Analysis or Content Details
**Llama-3-8B:**
* **PopQA:** Q-Anchored (exact question) is approximately 45, A-Anchored (exact question) is approximately 30, Q-Anchored (random) is approximately 10, A-Anchored (random) is approximately 5.
* **TriviaQA:** Q-Anchored (exact question) is approximately 80, A-Anchored (exact question) is approximately 40, Q-Anchored (random) is approximately 10, A-Anchored (random) is approximately 5.
* **HotpotQA:** Q-Anchored (exact question) is approximately 75, A-Anchored (exact question) is approximately 20, Q-Anchored (random) is approximately 10, A-Anchored (random) is approximately 5.
* **NQ:** Q-Anchored (exact question) is approximately 25, A-Anchored (exact question) is approximately 10, Q-Anchored (random) is approximately 5, A-Anchored (random) is approximately 5.
**Llama-3-70B:**
* **PopQA:** Q-Anchored (exact question) is approximately 50, A-Anchored (exact question) is approximately 35, Q-Anchored (random) is approximately 10, A-Anchored (random) is approximately 5.
* **TriviaQA:** Q-Anchored (exact question) is approximately 80, A-Anchored (exact question) is approximately 45, Q-Anchored (random) is approximately 10, A-Anchored (random) is approximately 5.
* **HotpotQA:** Q-Anchored (exact question) is approximately 75, A-Anchored (exact question) is approximately 25, Q-Anchored (random) is approximately 10, A-Anchored (random) is approximately 5.
* **NQ:** Q-Anchored (exact question) is approximately 25, A-Anchored (exact question) is approximately 10, Q-Anchored (random) is approximately 5, A-Anchored (random) is approximately 5.
**Mistral-7B-v0.3:**
* **PopQA:** Q-Anchored (exact question) is approximately 40, A-Anchored (exact question) is approximately 30, Q-Anchored (random) is approximately 10, A-Anchored (random) is approximately 5.
* **TriviaQA:** Q-Anchored (exact question) is approximately 80, A-Anchored (exact question) is approximately 40, Q-Anchored (random) is approximately 10, A-Anchored (random) is approximately 5.
* **HotpotQA:** Q-Anchored (exact question) is approximately 75, A-Anchored (exact question) is approximately 20, Q-Anchored (random) is approximately 10, A-Anchored (random) is approximately 5.
* **NQ:** Q-Anchored (exact question) is approximately 25, A-Anchored (exact question) is approximately 10, Q-Anchored (random) is approximately 5, A-Anchored (random) is approximately 5.
Across all models, the "Q-Anchored (exact question)" consistently shows the highest flip rate, followed by "A-Anchored (exact question)". The "random" anchoring methods have significantly lower flip rates.
### Key Observations
* The "TriviaQA" dataset consistently results in the highest prediction flip rates across all models and anchoring methods.
* The "NQ" dataset consistently results in the lowest prediction flip rates across all models and anchoring methods.
* The difference between "exact question" and "random" anchoring is substantial, indicating that anchoring on the exact question significantly increases the likelihood of a prediction flip.
* Llama-3-70B generally shows slightly higher flip rates than Llama-3-8B, while Mistral-7B-v0.3 is generally similar to Llama-3-8B.
### Interpretation
The data suggests that the prediction flip rate is highly dependent on both the model used and the dataset being evaluated. The high flip rates observed on TriviaQA may indicate that this dataset contains questions that are particularly sensitive to subtle changes in input or context. The lower flip rates on NQ suggest that this dataset is more robust or that the models are more confident in their predictions for this dataset.
The significant difference between "exact question" and "random" anchoring highlights the importance of context in these models. Anchoring on the exact question provides a stronger signal, leading to a higher probability of a prediction flip. This could be due to the models being more sensitive to specific keywords or phrases in the question.
The relatively consistent performance of the three models suggests that they share similar vulnerabilities and strengths in terms of prediction stability. The slight advantage of Llama-3-70B could be attributed to its larger size and increased capacity for learning complex relationships. Overall, the data provides valuable insights into the behavior of these language models and the factors that influence their prediction stability.