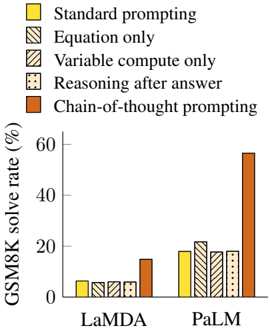
## Bar Chart: GSM8K Solve Rate by Prompting Method
### Overview
The image is a bar chart comparing the GSM8K solve rate (in percentage) for two language models, LaMDA and PaLM, using different prompting methods. The prompting methods are: Standard prompting, Equation only, Variable compute only, Reasoning after answer, and Chain-of-thought prompting.
### Components/Axes
* **Y-axis:** GSM8K solve rate (%), ranging from 0 to 60.
* **X-axis:** Language models: LaMDA and PaLM.
* **Legend (top-left):**
* Yellow: Standard prompting
* Diagonal Lines: Equation only
* Horizontal Lines: Variable compute only
* Dotted: Reasoning after answer
* Brown: Chain-of-thought prompting
### Detailed Analysis
* **LaMDA:**
* Standard prompting (Yellow): Approximately 6%
* Equation only (Diagonal Lines): Approximately 6%
* Variable compute only (Horizontal Lines): Approximately 6%
* Reasoning after answer (Dotted): Approximately 6%
* Chain-of-thought prompting (Brown): Approximately 14%
* **PaLM:**
* Standard prompting (Yellow): Approximately 18%
* Equation only (Diagonal Lines): Approximately 22%
* Variable compute only (Horizontal Lines): Approximately 18%
* Reasoning after answer (Dotted): Approximately 18%
* Chain-of-thought prompting (Brown): Approximately 58%
### Key Observations
* For LaMDA, all prompting methods except Chain-of-thought prompting yield similar solve rates, around 6%. Chain-of-thought prompting significantly improves the solve rate to approximately 14%.
* For PaLM, Chain-of-thought prompting dramatically outperforms all other prompting methods, achieving a solve rate of approximately 58%. The other methods yield solve rates between 18% and 22%.
* PaLM consistently outperforms LaMDA across all prompting methods.
* Chain-of-thought prompting is the most effective method for both models, but its impact is much more pronounced for PaLM.
### Interpretation
The data suggests that Chain-of-thought prompting is a highly effective technique for improving the performance of language models on the GSM8K math problem-solving benchmark. The significant difference in performance between Chain-of-thought prompting and other methods, especially for PaLM, indicates that this prompting strategy enables the model to better reason through the problem and arrive at the correct solution. The fact that PaLM consistently outperforms LaMDA suggests that PaLM has a superior architecture or training data that allows it to better leverage the benefits of Chain-of-thought prompting. The similar performance of the other prompting methods for LaMDA suggests that these methods are not as effective at eliciting the model's reasoning capabilities.