\n
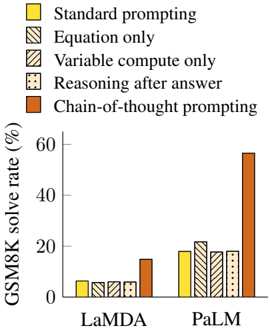
## Bar Chart: GSM8K Solve Rate by Prompting Method and Model
### Overview
This bar chart compares the GSM8K solve rate (in percentage) for two language models, LaMDA and PaLM, across five different prompting methods. The solve rate is represented by the height of the bars.
### Components/Axes
* **X-axis:** Model - LaMDA and PaLM.
* **Y-axis:** GSM8K solve rate (%). Scale ranges from 0 to 60, with increments of 10.
* **Legend:** Located in the top-left corner, it defines the color-coding for each prompting method:
* Yellow: Standard prompting
* Light Gray (diagonal lines): Equation only
* Dark Gray (diagonal lines): Variable compute only
* Dotted: Reasoning after answer
* Orange: Chain-of-thought prompting
### Detailed Analysis
The chart consists of 10 bars, grouped by model (LaMDA and PaLM) and prompting method.
**LaMDA:**
* **Standard prompting (Yellow):** Approximately 8% solve rate.
* **Equation only (Light Gray):** Approximately 4% solve rate.
* **Variable compute only (Dark Gray):** Approximately 6% solve rate.
* **Reasoning after answer (Dotted):** Approximately 5% solve rate.
* **Chain-of-thought prompting (Orange):** Approximately 18% solve rate.
**PaLM:**
* **Standard prompting (Yellow):** Approximately 22% solve rate.
* **Equation only (Light Gray):** Approximately 21% solve rate.
* **Variable compute only (Dark Gray):** Approximately 20% solve rate.
* **Reasoning after answer (Dotted):** Approximately 18% solve rate.
* **Chain-of-thought prompting (Orange):** Approximately 58% solve rate.
The bars for PaLM are generally higher than those for LaMDA, indicating a better solve rate across all prompting methods. Chain-of-thought prompting consistently yields the highest solve rate for both models, but the effect is much more pronounced for PaLM.
### Key Observations
* Chain-of-thought prompting significantly improves the GSM8K solve rate for both LaMDA and PaLM.
* PaLM consistently outperforms LaMDA across all prompting methods.
* The difference in performance between prompting methods is more substantial for PaLM than for LaMDA.
* The solve rates for Equation only, Variable compute only, and Reasoning after answer are relatively similar for both models.
### Interpretation
The data suggests that the Chain-of-thought prompting method is highly effective in improving the performance of large language models on mathematical reasoning tasks, as measured by the GSM8K benchmark. The substantial increase in solve rate for PaLM when using this method indicates that PaLM is particularly well-suited to benefit from this type of prompting. The relatively low solve rates for the other prompting methods suggest that simply providing equations, computing variables, or reasoning after generating an answer is not as effective as guiding the model through a step-by-step reasoning process. The consistent outperformance of PaLM over LaMDA suggests differences in model architecture or training data that make PaLM more capable of leveraging these prompting techniques. The large gap between PaLM with Chain-of-thought prompting and all other methods is a notable outlier, highlighting the power of this technique.