## Bar Chart: GSM8K Solve Rate Comparison Across Prompting Methods for LaMDA and PaLM
### Overview
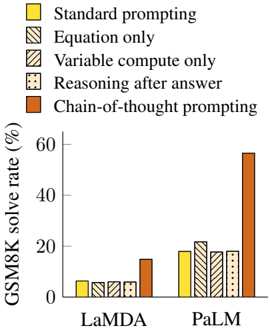
The chart compares the performance of five prompting methods on two language models (LaMDA and PaLM) in solving GSM8K math problems. The y-axis represents solve rate percentage, while the x-axis categorizes results by model. Chain-of-thought prompting shows dramatically higher performance for PaLM compared to other methods.
### Components/Axes
- **X-axis**: Model names ("LaMDA", "PaLM")
- **Y-axis**: "GSM8K solve rate (%)" (0-60% scale)
- **Legend**:
- Yellow: Standard prompting
- Striped: Equation only
- Dotted: Variable compute only
- Crosshatched: Reasoning after answer
- Orange: Chain-of-thought prompting
### Detailed Analysis
**LaMDA Results**:
- All methods show near-identical performance (~5% solve rate)
- Chain-of-thought prompting (orange) slightly outperforms others at ~15%
**PaLM Results**:
- Standard prompting (yellow): ~18%
- Equation only (striped): ~20%
- Variable compute only (dotted): ~18%
- Reasoning after answer (crosshatched): ~18%
- Chain-of-thought prompting (orange): ~58% (3x higher than other methods)
### Key Observations
1. **PaLM's Superiority with Chain-of-Thought**: The orange bar for PaLM is 3-4x taller than all other bars, indicating chain-of-thought prompting enables near-human-level performance on these problems.
2. **LaMDA's Uniform Performance**: All prompting methods yield similar low results for LaMDA, suggesting limited reasoning capability regardless of approach.
3. **PaLM's Method-Specific Gains**: While PaLM performs better overall, chain-of-thought prompting creates a stark performance gap compared to other methods.
### Interpretation
The data reveals fundamental architectural differences between LaMDA and PaLM in handling reasoning tasks. PaLM's transformer-based architecture appears better suited for chain-of-thought prompting, which mimics human step-by-step reasoning. This suggests:
- PaLM's design enables better decomposition of complex problems
- LaMDA may lack internal mechanisms to benefit from explicit reasoning scaffolding
- Chain-of-thought prompting acts as a "reasoning amplifier" for PaLM but not LaMDA
The 58% solve rate for PaLM with chain-of-thought prompting approaches human performance levels on these problems, demonstrating the effectiveness of this prompting strategy for advanced language models.