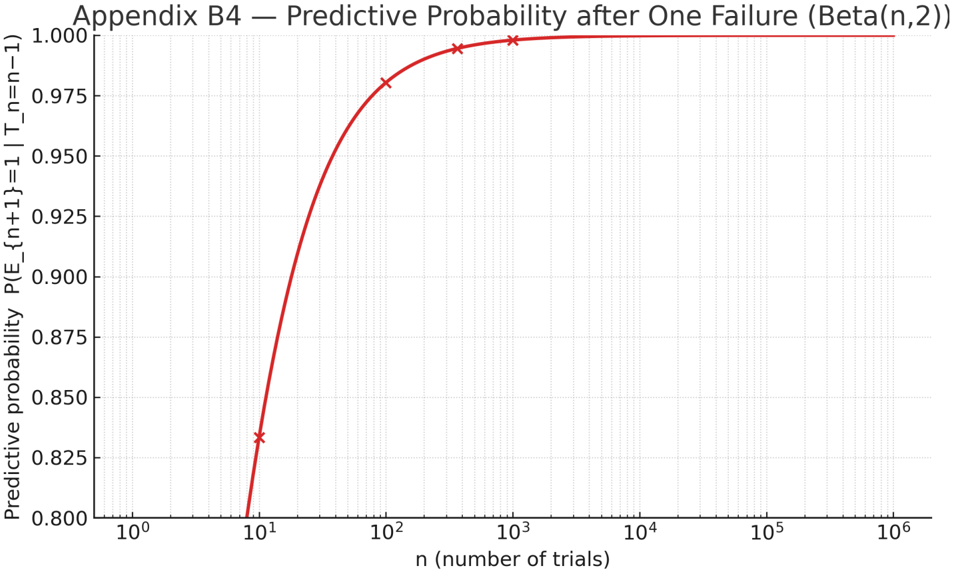
## Line Chart: Predictive Probability after One Failure (Beta(n,2))
### Overview
The chart illustrates the relationship between the number of trials (`n`) and the predictive probability of success (`P(E_{n+1}=1 | T_n=n−1)`) under a Beta(n,2) distribution. The probability increases with `n`, approaching 1.0 as trials grow, with a logarithmic scale on the x-axis.
### Components/Axes
- **X-axis**: `n` (number of trials), logarithmic scale from 10⁰ to 10⁶.
- **Y-axis**: Predictive probability, linear scale from 0.800 to 1.000.
- **Legend**: Located in the top-right corner, labeled "Beta(n,2)" with a red line and cross markers.
- **Line**: Red curve with cross markers at specific `n` values (10¹, 10², 10³, 10⁴).
### Detailed Analysis
- **At n=10¹ (10 trials)**: Probability ≈ 0.825 (cross marker).
- **At n=10² (100 trials)**: Probability ≈ 0.975 (cross marker).
- **At n=10³ (1,000 trials)**: Probability ≈ 0.995 (cross marker).
- **At n=10⁴ (10,000 trials)**: Probability ≈ 1.000 (cross marker).
- **Trend**: The red line rises steeply from n=10 to n=100, then gradually approaches 1.0, plateauing after n=10⁴.
### Key Observations
1. **Rapid Initial Growth**: Probability jumps from 0.825 to 0.975 between n=10 and n=100.
2. **Asymptotic Behavior**: Probability stabilizes near 1.0 for n ≥ 10⁴, indicating diminishing returns.
3. **Logarithmic X-axis**: Emphasizes scalability across orders of magnitude.
### Interpretation
The Beta(n,2) model demonstrates that predictive probability of success after one failure converges to certainty as trials increase. The steep rise in early trials (n=10 to n=100) suggests that initial data collection significantly impacts confidence in predictions. The plateau at high `n` implies that beyond ~10,000 trials, additional experiments yield negligible improvements in predictive accuracy. This aligns with Bayesian updating principles, where prior failures (encoded in the Beta(2) prior) are gradually outweighed by accumulating successes. The logarithmic x-axis highlights the model’s utility in scenarios requiring large-scale experimentation, such as reliability testing or A/B testing frameworks.