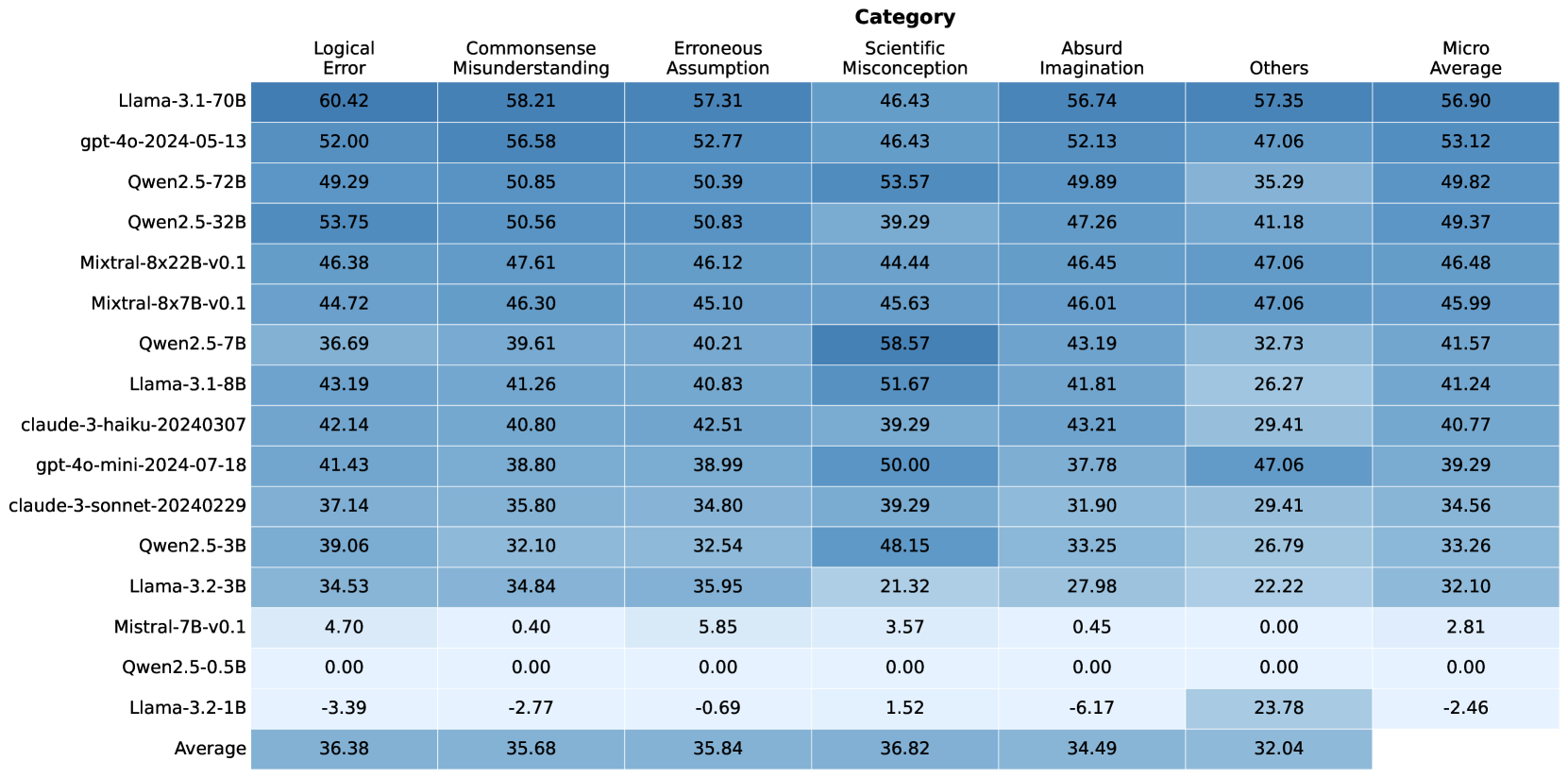
## Table: AI Model Performance Across Error Categories
### Overview
This table compares the performance of various large language models (LLMs) across seven error categories: Logical Error, Commonsense Misunderstanding, Erroneous Assumption, Scientific Misconception, Absurd Imagination, Others, and Micro Average. The data includes 15 models, with numerical values representing error rates or scores (higher values indicate worse performance). The final row shows averages across all models.
### Components/Axes
- **Rows**: AI models (e.g., Llama-3.1-70B, gpt-4o-2024-05-13, Qwen2.5-72B, etc.)
- **Columns**: Error categories (Logical Error, Commonsense Misunderstanding, Erroneous Assumption, Scientific Misconception, Absurd Imagination, Others, Micro Average)
- **Values**: Numerical scores (e.g., 60.42 for Llama-3.1-70B under Logical Error)
- **Special Cases**:
- Mistral-7B-v0.1 has 0.00 in multiple categories.
- Llama-3.2-1B has negative values (-3.39, -2.77, -0.69, 1.52, -6.17, 23.78, -2.46).
### Detailed Analysis
#### Logical Error
- Highest: Llama-3.1-70B (60.42)
- Lowest: Llama-3.2-1B (-3.39)
- Average: 36.38
#### Commonsense Misunderstanding
- Highest: Llama-3.1-70B (58.21)
- Lowest: Llama-3.2-1B (-2.77)
- Average: 35.68
#### Erroneous Assumption
- Highest: Llama-3.1-70B (57.31)
- Lowest: Llama-3.2-1B (-0.69)
- Average: 35.84
#### Scientific Misconception
- Highest: Qwen2.5-7B (58.57)
- Lowest: Mistral-7B-v0.1 (3.57)
- Average: 36.82
#### Absurd Imagination
- Highest: Llama-3.1-70B (56.74)
- Lowest: Llama-3.2-1B (-6.17)
- Average: 34.49
#### Others
- Highest: Llama-3.1-70B (57.35)
- Lowest: Llama-3.2-1B (23.78)
- Average: 32.04
#### Micro Average
- Highest: Llama-3.1-70B (56.90)
- Lowest: Llama-3.2-1B (-2.46)
- Overall Average: 32.04
### Key Observations
1. **Performance Variance**:
- Llama-3.1-70B dominates across most categories, with the highest Micro Average (56.90).
- Llama-3.2-1B underperforms significantly, with negative values in multiple categories and a Micro Average of -2.46.
- Qwen2.5-7B excels in Scientific Misconception (58.57) but lags in Others (32.73).
2. **Model Size Correlation**:
- Larger models (e.g., Llama-3.1-70B, Qwen2.5-72B) generally have higher error rates.
- Smaller models (e.g., Mistral-7B-v0.1, Qwen2.5-0.5B) show near-zero or minimal errors in some categories.
3. **Anomalies**:
- Negative values for Llama-3.2-1B suggest potential data inconsistencies or unique evaluation metrics.
- Mistral-7B-v0.1 has 0.00 in Logical Error, Commonsense Misunderstanding, and Scientific Misconception, indicating either perfect performance or missing data.
4. **Category-Specific Trends**:
- **Scientific Misconception**: Qwen2.5-7B (58.57) and gpt-4o-mini (50.00) perform poorly.
- **Absurd Imagination**: Llama-3.1-70B (56.74) and gpt-4o-2024-05-13 (52.13) show high error rates.
- **Others**: Llama-3.1-70B (57.35) and gpt-4o-mini (47.06) have the highest scores.
### Interpretation
The data highlights significant disparities in model performance across error categories. Larger models like Llama-3.1-70B and Qwen2.5-72B exhibit higher error rates, particularly in logical and scientific reasoning, suggesting potential overfitting or complexity-related challenges. Smaller models (e.g., Mistral-7B-v0.1) show near-zero errors in some categories, possibly due to specialized training or simpler architectures. The negative values for Llama-3.2-1B raise questions about data validity or evaluation methodology. The Micro Average (32.04) indicates that, on average, models struggle most with "Others" and "Absurd Imagination" categories, pointing to gaps in handling ambiguous or creative tasks. This analysis underscores the need for targeted improvements in specific error domains to enhance overall model robustness.