## Line Charts: Performance of Prompting Methods on Various Tasks
### Overview
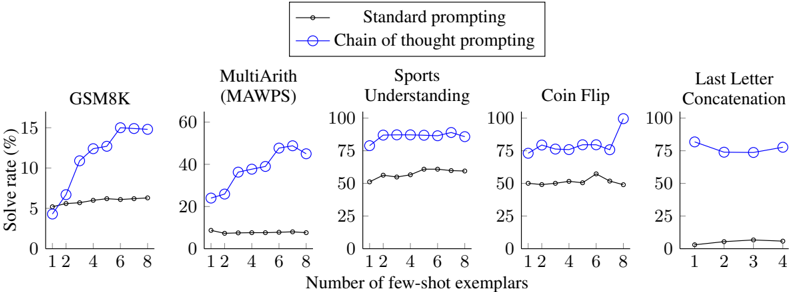
The image presents a series of five line charts comparing the performance of "Standard prompting" and "Chain of thought prompting" methods across different tasks: GSM8K, MultiArith (MAWPS), Sports Understanding, Coin Flip, and Last Letter Concatenation. The charts illustrate how the solve rate (%) changes with the number of few-shot exemplars.
### Components/Axes
* **Title:** Performance of Prompting Methods on Various Tasks (inferred)
* **X-axis:** Number of few-shot exemplars (values: 1, 2, 4, 6, 8 for the first four charts; 1, 2, 3, 4 for the last chart)
* **Y-axis:** Solve rate (%) (ranges vary for each chart, but all start at 0)
* GSM8K: 0 to 15
* MultiArith (MAWPS): 0 to 60
* Sports Understanding: 0 to 100
* Coin Flip: 0 to 100
* Last Letter Concatenation: 0 to 100
* **Legend (top-center):**
* Black line with circles: Standard prompting
* Blue line with circles: Chain of thought prompting
* **Chart Titles (top of each chart):**
* GSM8K
* MultiArith (MAWPS)
* Sports Understanding
* Coin Flip
* Last Letter Concatenation
### Detailed Analysis
**1. GSM8K**
* **Standard prompting (black):** Relatively flat, hovering around 6% solve rate.
* (1, ~5%), (2, ~6%), (4, ~6%), (6, ~6%), (8, ~6%)
* **Chain of thought prompting (blue):** Increases sharply with more exemplars, reaching a plateau around 15%.
* (1, ~5%), (2, ~11%), (4, ~14%), (6, ~15%), (8, ~15%)
**2. MultiArith (MAWPS)**
* **Standard prompting (black):** Low and relatively constant, around 7-8%.
* (1, ~8%), (2, ~8%), (4, ~8%), (6, ~8%), (8, ~8%)
* **Chain of thought prompting (blue):** Increases with more exemplars, reaching a plateau around 45-50%.
* (1, ~24%), (2, ~35%), (4, ~40%), (6, ~48%), (8, ~45%)
**3. Sports Understanding**
* **Standard prompting (black):** Slightly increasing, from around 55% to 60%.
* (1, ~54%), (2, ~55%), (4, ~57%), (6, ~60%), (8, ~60%)
* **Chain of thought prompting (blue):** High and relatively constant, around 85-90%.
* (1, ~80%), (2, ~88%), (4, ~88%), (6, ~88%), (8, ~88%)
**4. Coin Flip**
* **Standard prompting (black):** Relatively flat, hovering around 50-55%.
* (1, ~50%), (2, ~50%), (4, ~50%), (6, ~52%), (8, ~50%)
* **Chain of thought prompting (blue):** Relatively flat, hovering around 75-80%, with a spike at 8 exemplars.
* (1, ~75%), (2, ~78%), (4, ~78%), (6, ~78%), (8, ~98%)
**5. Last Letter Concatenation**
* **Standard prompting (black):** Very low and relatively constant, around 2-3%.
* (1, ~2%), (2, ~2%), (3, ~3%), (4, ~3%)
* **Chain of thought prompting (blue):** Starts around 80% and decreases slightly, then stabilizes around 75-80%.
* (1, ~80%), (2, ~73%), (3, ~75%), (4, ~78%)
### Key Observations
* Chain of thought prompting generally outperforms standard prompting across all tasks.
* The impact of increasing the number of few-shot exemplars varies by task and prompting method. For some tasks (e.g., GSM8K, MultiArith), chain of thought prompting benefits significantly from more exemplars.
* For some tasks (e.g., Sports Understanding, Coin Flip), chain of thought prompting achieves high performance even with few exemplars.
* Last Letter Concatenation is the only task where the performance of chain of thought prompting decreases slightly with more exemplars.
* Standard prompting shows minimal improvement with increasing exemplars in most tasks.
### Interpretation
The data suggests that "Chain of thought prompting" is a more effective strategy than "Standard prompting" for the tasks evaluated. The effectiveness of "Chain of thought prompting" is particularly evident in tasks like GSM8K and MultiArith, where performance improves significantly with more examples. This indicates that providing the model with a chain of reasoning steps helps it to solve complex problems more effectively.
The relatively flat performance of "Standard prompting" across different numbers of exemplars suggests that simply providing more examples without guiding the model's reasoning process is not sufficient for improving performance on these tasks.
The slight decrease in performance of "Chain of thought prompting" on the Last Letter Concatenation task with more exemplars could indicate that the model is overfitting to the training data or that the task is not well-suited for this prompting method.