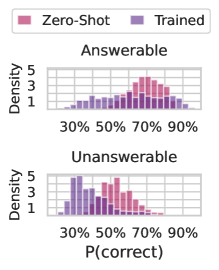
## Bar Chart: Performance Comparison of Zero-Shot and Trained Models
### Overview
The image is a bar chart comparing the performance of two methods—**Zero-Shot** (pink) and **Trained** (purple)—across two categories: **Answerable** and **Unanswerable** questions. The x-axis represents the probability of correct answers (P(correct)) in increments of 30%, 50%, 70%, and 90%, while the y-axis shows density values ranging from 0 to 5.
### Components/Axes
- **Legend**:
- **Zero-Shot**: Pink bars.
- **Trained**: Purple bars.
- **X-Axis (P(correct))**: Labeled with percentages (30%, 50%, 70%, 90%).
- **Y-Axis (Density)**: Labeled "Density" with values from 0 to 5.
- **Categories**:
- **Answerable**: Top section of the chart.
- **Unanswerable**: Bottom section of the chart.
### Detailed Analysis
#### Answerable Questions
- **Zero-Shot (Pink)**:
- Density peaks at **70% P(correct)**, with a moderate spread between 50% and 90%.
- Lower density at 30% and 50%.
- **Trained (Purple)**:
- Density peaks at **50% P(correct)**, with a broader distribution across 30% to 70%.
- Lower density at 90%.
#### Unanswerable Questions
- **Zero-Shot (Pink)**:
- Density peaks at **30% P(correct)**, with a sharp drop at higher percentages.
- Minimal presence at 50% and 70%.
- **Trained (Purple)**:
- Density peaks at **50% P(correct)**, with a flatter distribution across 30% to 70%.
- Slightly higher density at 70% compared to Zero-Shot.
### Key Observations
1. **Zero-Shot** performs better on **Answerable** questions, particularly at higher P(correct) thresholds (70–90%).
2. **Trained** models show higher density in **Unanswerable** questions, peaking at 50% P(correct), suggesting improved ability to identify unanswerable queries.
3. **Zero-Shot** has a narrower distribution for Answerable questions, while **Trained** models exhibit broader performance across P(correct) ranges.
### Interpretation
The data suggests that **Trained models** are more effective at distinguishing **Unanswerable** questions, likely due to better generalization or calibration. However, **Zero-Shot** models outperform in **Answerable** scenarios, especially at higher confidence levels. This trade-off highlights a potential design consideration: training improves reliability in rejecting unanswerable queries but may reduce performance on high-confidence answerable tasks. The density distributions imply that **Trained** models are less certain about their answers in Answerable cases, while **Zero-Shot** models are more decisive but less accurate in Unanswerable scenarios.