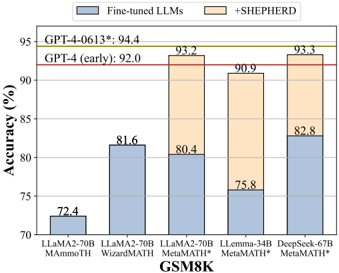
## Bar Chart: Model Accuracy Comparison on GSM8K Benchmark
### Overview
The chart compares the accuracy of different large language models (LLMs) on the GSM8K benchmark, evaluating two approaches: "Fine-tuned LLMs" (blue) and "+SHEPHERD" (orange). The y-axis represents accuracy in percentage, while the x-axis lists five models: LLama2-70B MAmmoTH, LLama2-70B WizardMATH, LLama2-70B MetaMATH*, LLaMA-34B MetaMATH*, and DeepSeek-67B MetaMATH*. Two reference lines are included: "GPT-4 (early): 92.0" (red) and "GPT-4-0613*: 94.4" (gold).
### Components/Axes
- **X-axis (Models)**:
- LLama2-70B MAmmoTH
- LLama2-70B WizardMATH
- LLama2-70B MetaMATH*
- LLaMA-34B MetaMATH*
- DeepSeek-67B MetaMATH*
- **Y-axis (Accuracy %)**: Ranges from 70% to 95%, with gridlines at 5% intervals.
- **Legend**:
- Blue: Fine-tuned LLMs
- Orange: +SHEPHERD
- **Title**: "GSM8K" (bottom center).
### Detailed Analysis
- **LLama2-70B MAmmoTH**:
- Fine-tuned LLMs: 72.4% (blue)
- +SHEPHERD: 93.2% (orange)
- **LLama2-70B WizardMATH**:
- Fine-tuned LLMs: 81.6% (blue)
- +SHEPHERD: 80.4% (orange)
- **LLama2-70B MetaMATH***:
- Fine-tuned LLMs: 75.8% (blue)
- +SHEPHERD: 90.9% (orange)
- **LLaMA-34B MetaMATH***:
- Fine-tuned LLMs: 82.8% (blue)
- +SHEPHERD: Not explicitly labeled (implied by bar height).
- **DeepSeek-67B MetaMATH***:
- Fine-tuned LLMs: 82.8% (blue)
- +SHEPHERD: 93.3% (orange)
### Key Observations
1. **+SHEPHERD consistently improves accuracy** across all models, with gains ranging from +17.4% (LLama2-70B MAmmoTH) to +7.5% (LLama2-70B WizardMATH).
2. **DeepSeek-67B MetaMATH*** achieves the highest accuracy (93.3%) with +SHEPHERD, surpassing all other models.
3. **LLama2-70B MAmmoTH** shows the largest improvement (+20.8%) when +SHEPHERD is applied.
4. **GPT-4 benchmarks** (92.0% and 94.4%) are not part of the chart but are referenced as external standards.
### Interpretation
The data demonstrates that the +SHEPHERD method significantly enhances the performance of LLMs on the GSM8K benchmark, particularly for models with lower baseline accuracy (e.g., LLama2-70B MAmmoTH). This suggests that +SHEPHERD may address limitations in fine-tuned models, such as reasoning gaps or domain-specific knowledge deficits. The consistent improvement across models implies that +SHEPHERD is a robust augmentation technique, though its effectiveness varies slightly depending on the base model. The absence of explicit values for LLaMA-34B MetaMATH* with +SHEPHERD introduces minor uncertainty, but its bar height aligns with the trend of higher accuracy for +SHEPHERD. The GPT-4 benchmarks highlight the gap between current LLMs and state-of-the-art performance, emphasizing the need for further optimization.