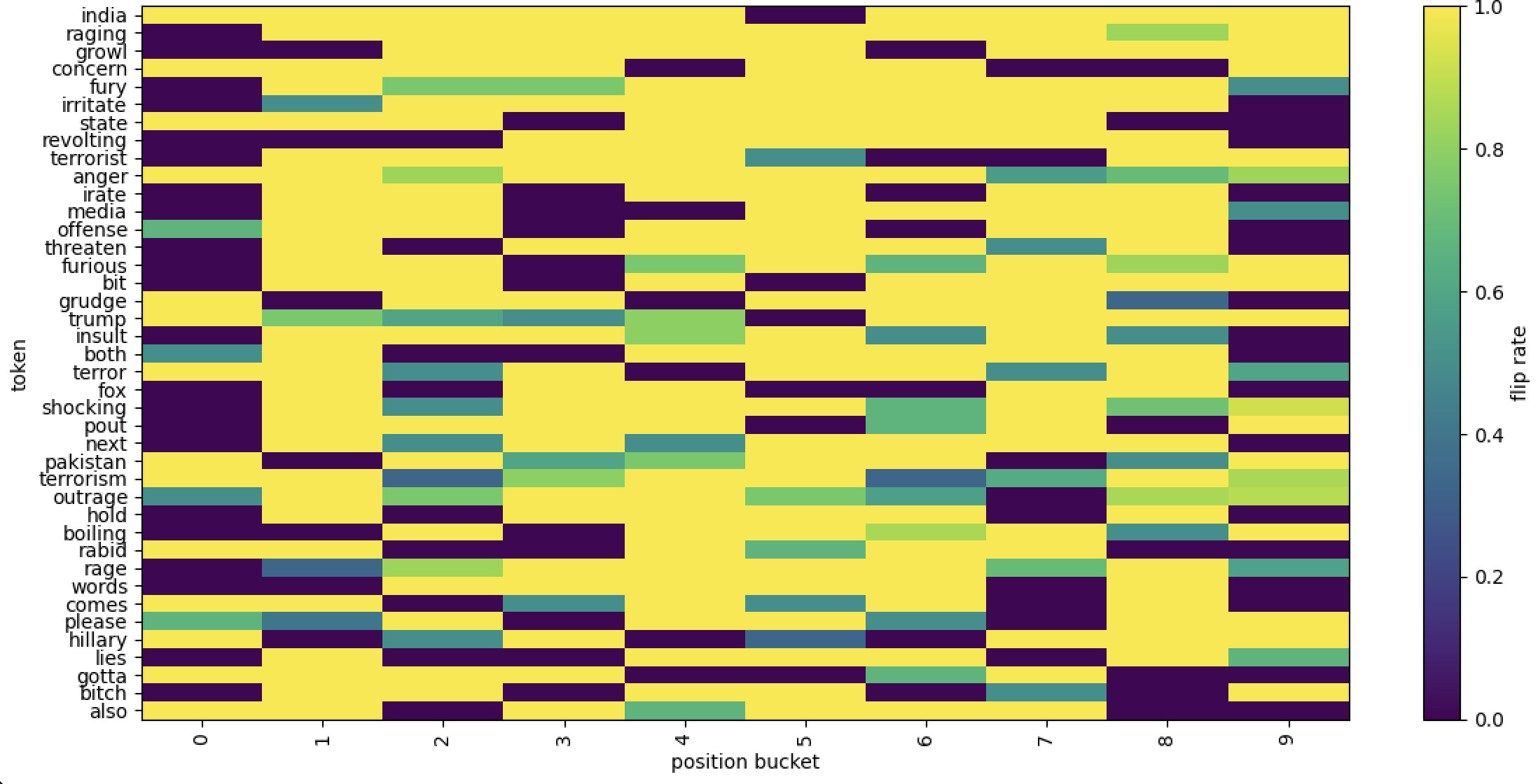
## [Heatmap]: Token Flip Rate by Position Bucket
### Overview
The image is a heatmap (2D grid plot) illustrating the **flip rate** (a measure of state change frequency) for various tokens (words) across 10 position buckets (0–9). The y-axis lists tokens, the x-axis lists position buckets, and a color bar (right) maps colors to flip rates (0.0 = dark purple, 1.0 = yellow; intermediate: teal = 0.4, green = 0.6, light green = 0.8).
### Components/Axes
- **Y-axis (Tokens):** 40 tokens (rows) in order:
`india, raging, growl, concern, fury, irritate, state, revolting, terrorist, anger, irate, media, offense, threaten, furious, bit, grudge, trump, insult, both, terror, fox, shocking, pout, next, pakistan, terrorism, outrage, hold, boiling, rabid, rage, words, comes, please, hillary, lies, gotta, bitch, also`
- **X-axis (Position Buckets):** 10 buckets (columns) labeled `0, 1, 2, 3, 4, 5, 6, 7, 8, 9`.
- **Color Bar (Legend):** Vertical bar on the right, labeled `flip rate`, with a gradient from 0.0 (dark purple) to 1.0 (yellow). Intermediate colors: teal (0.4), green (0.6), light green (0.8).
### Detailed Analysis (Key Trends by Token)
We analyze flip rates (color) across position buckets (0–9) for each token, focusing on patterns:
#### 1. High Flip Rate (Yellow, 1.0)
- **Early Positions (0–1):** Tokens like `india, raging, growl, concern, state, media, outrage, rabid, comes, hillary, also` have high rates here.
- **Late Positions (3–9):** Tokens like `revolting, irate, threaten, bit, insult, fox, pout, hold, boiling, words, lies, gotta, bitch` have high rates here (low in 0–2).
#### 2. Low Flip Rate (Dark Purple, 0.0)
- **Early Positions (0–2):** Tokens like `revolting, irate, threaten, bit, insult, fox, pout, hold, boiling, words, lies, gotta, bitch` have low rates here (high in 3–9).
- **Late Positions (1–9):** Tokens like `grudge, rabid, comes, hillary, also` have low rates here (high only in 0).
#### 3. Medium Flip Rate (Teal = 0.4, Green = 0.6)
- **Teal (0.4):** Seen in `irritate (1), terror (2–3, 6–9), shocking (2–3), pakistan (2), terrorism (2, 6–9), please (1)`.
- **Green (0.6):** Seen in `fury (2–3), offense (0–1), trump (1–4), terrorism (3), rage (2–3), please (0)`.
### Key Observations
- **Position Bucket Patterns:**
- Position `0` often has high/medium rates (e.g., `india, raging, growl, concern, state, media, outrage, rabid, comes, hillary, also, offense, trump, terror, please`).
- Position `1` is mixed (low for most, medium for `irritate, trump, please`).
- Position `2` is mixed (low for most, medium for `fury, terror, shocking, pakistan, terrorism, rage`).
- Positions `3–9` are mostly high for many tokens (e.g., `revolting, irate, threaten, bit, insult, fox, pout, hold, boiling, words, lies, gotta, bitch`), with exceptions (e.g., `terrorist, trump, next, pakistan, terrorism, please`).
- **Token-Specific Trends:**
- `trump`: High at `0`, medium (0.6) at `1–4`, low at `5–9` (more state changes early).
- `hillary`: High at `0`, low at `1–9` (fewer changes after the first position).
- `terrorist`: Low at `0–2, 5–7`, medium (0.4) at `4`, high at `3, 8–9` (unusual pattern).
### Interpretation
This heatmap likely analyzes **token state changes** (e.g., in NLP tasks like sentiment analysis, part-of-speech tagging, or model interpretability) across text positions (e.g., word positions in a sentence/document).
- **Position Impact:** Later positions (3–9) often have higher flip rates, suggesting tokens in later text positions are more likely to change state (e.g., a model’s prediction for a word changes as it appears later in a sentence).
- **Token Behavior:** Tokens related to anger (`fury, irritate, anger, irate, furious, rage`), terrorism (`terrorist, terror, terrorism`), and politics (`trump, hillary`) show distinct flip patterns, indicating how their “state” (e.g., sentiment, classification) evolves with position.
- **Anomalies:** Tokens like `grudge, rabid, comes, hillary, also` have high flip rates only at position `0`, then low—suggesting rare state changes after the first position.
This data helps identify how tokens behave across text positions, informing NLP model design or interpretability (e.g., why a model’s prediction for a word changes with its location in a sentence).