TECHNICAL ASSET FINGERPRINT
fd558bf51abd7f3aaf12ad2f
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: gemini-2.0-flash VERSION 1
RUNTIME: nugit/gemini/gemini-2.0-flash
INTEL_VERIFIED
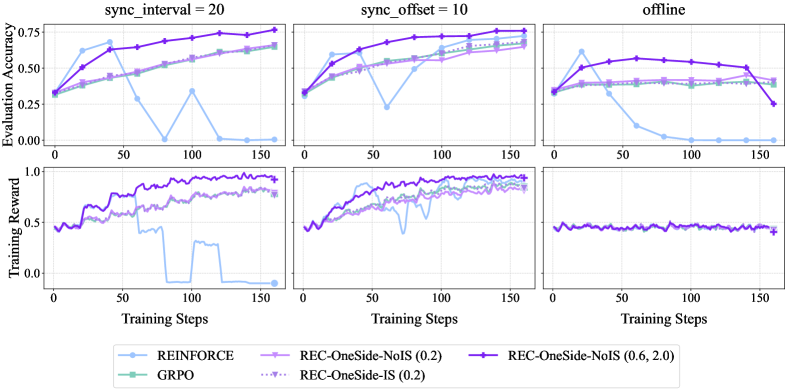
## Line Charts: Evaluation Accuracy and Training Reward vs. Training Steps
### Overview
The image presents a series of line charts comparing the performance of different reinforcement learning algorithms under varying synchronization conditions. The charts are arranged in a 2x3 grid, with the top row displaying "Evaluation Accuracy" and the bottom row displaying "Training Reward" against "Training Steps". The columns represent different synchronization settings: "sync_interval = 20", "sync_offset = 10", and "offline". The legend at the bottom identifies the algorithms being compared: REINFORCE, GRPO, REC-OneSide-NoIS (0.2), REC-OneSide-IS (0.2), and REC-OneSide-NoIS (0.6, 2.0).
### Components/Axes
* **Rows:**
* Top Row: Evaluation Accuracy (y-axis, ranging from 0.00 to 0.75) vs. Training Steps (x-axis, ranging from 0 to 150)
* Bottom Row: Training Reward (y-axis, ranging from 0.0 to 1.0) vs. Training Steps (x-axis, ranging from 0 to 150)
* **Columns:**
* Left Column: sync\_interval = 20
* Middle Column: sync\_offset = 10
* Right Column: offline
* **X-axis (all charts):** Training Steps, ranging from 0 to 150. Increments are marked at 0, 50, 100, and 150.
* **Y-axis (top row):** Evaluation Accuracy, ranging from 0.00 to 0.75. Increments are marked at 0.00, 0.25, 0.50, and 0.75.
* **Y-axis (bottom row):** Training Reward, ranging from 0.0 to 1.0. Increments are marked at 0.0, 0.5, and 1.0.
* **Legend (bottom):**
* REINFORCE (light blue line with circle markers)
* GRPO (light green line with square markers)
* REC-OneSide-NoIS (0.2) (light purple line with plus markers)
* REC-OneSide-IS (0.2) (dotted light purple line with triangle markers)
* REC-OneSide-NoIS (0.6, 2.0) (dark purple line with star markers)
### Detailed Analysis
**Top Row: Evaluation Accuracy**
* **sync\_interval = 20:**
* REINFORCE (light blue): Starts around 0.3, increases to approximately 0.6 by step 50, then drops sharply to near 0 by step 150.
* GRPO (light green): Starts around 0.3, gradually increases to approximately 0.5 by step 150.
* REC-OneSide-NoIS (0.2) (light purple): Starts around 0.4, gradually increases to approximately 0.65 by step 150.
* REC-OneSide-IS (0.2) (dotted light purple): Starts around 0.4, gradually increases to approximately 0.6 by step 150.
* REC-OneSide-NoIS (0.6, 2.0) (dark purple): Starts around 0.3, increases to approximately 0.75 by step 150.
* **sync\_offset = 10:**
* REINFORCE (light blue): Starts around 0.3, increases to approximately 0.6 by step 50, then decreases to approximately 0.45 by step 150.
* GRPO (light green): Starts around 0.3, gradually increases to approximately 0.65 by step 150.
* REC-OneSide-NoIS (0.2) (light purple): Starts around 0.4, gradually increases to approximately 0.7 by step 150.
* REC-OneSide-IS (0.2) (dotted light purple): Starts around 0.4, gradually increases to approximately 0.65 by step 150.
* REC-OneSide-NoIS (0.6, 2.0) (dark purple): Starts around 0.3, increases to approximately 0.75 by step 150.
* **offline:**
* REINFORCE (light blue): Starts around 0.4, increases to approximately 0.65 by step 25, then decreases to near 0 by step 150.
* GRPO (light green): Starts around 0.4, remains relatively constant around 0.45 by step 150.
* REC-OneSide-NoIS (0.2) (light purple): Starts around 0.4, remains relatively constant around 0.45 by step 150.
* REC-OneSide-IS (0.2) (dotted light purple): Starts around 0.4, remains relatively constant around 0.45 by step 150.
* REC-OneSide-NoIS (0.6, 2.0) (dark purple): Starts around 0.4, remains relatively constant around 0.6 by step 150.
**Bottom Row: Training Reward**
* **sync\_interval = 20:**
* REINFORCE (light blue): Starts around 0.5, increases to approximately 0.9 by step 50, then drops sharply to near 0 by step 150.
* GRPO (light green): Starts around 0.4, gradually increases to approximately 0.7 by step 150.
* REC-OneSide-NoIS (0.2) (light purple): Starts around 0.4, gradually increases to approximately 0.8 by step 150.
* REC-OneSide-IS (0.2) (dotted light purple): Not visible in this chart.
* REC-OneSide-NoIS (0.6, 2.0) (dark purple): Starts around 0.5, increases to approximately 0.95 by step 150.
* **sync\_offset = 10:**
* REINFORCE (light blue): Starts around 0.4, increases to approximately 0.7 by step 50, then decreases to approximately 0.6 by step 150.
* GRPO (light green): Starts around 0.4, gradually increases to approximately 0.8 by step 150.
* REC-OneSide-NoIS (0.2) (light purple): Starts around 0.4, gradually increases to approximately 0.9 by step 150.
* REC-OneSide-IS (0.2) (dotted light purple): Starts around 0.4, gradually increases to approximately 0.8 by step 150.
* REC-OneSide-NoIS (0.6, 2.0) (dark purple): Starts around 0.4, increases to approximately 0.95 by step 150.
* **offline:**
* REINFORCE (light blue): Not visible in this chart.
* GRPO (light green): Not visible in this chart.
* REC-OneSide-NoIS (0.2) (light purple): Starts around 0.45, remains relatively constant around 0.45 by step 150.
* REC-OneSide-IS (0.2) (dotted light purple): Not visible in this chart.
* REC-OneSide-NoIS (0.6, 2.0) (dark purple): Starts around 0.45, remains relatively constant around 0.45 by step 150.
### Key Observations
* REINFORCE performs well initially in the "sync\_interval = 20" and "sync\_offset = 10" conditions but degrades significantly over time, especially in the "offline" setting.
* REC-OneSide-NoIS (0.6, 2.0) generally achieves the highest evaluation accuracy and training reward across all conditions.
* GRPO and REC-OneSide-NoIS (0.2) show more stable performance compared to REINFORCE, but their peak performance is generally lower than REC-OneSide-NoIS (0.6, 2.0).
* The "offline" setting appears to negatively impact the performance of REINFORCE significantly.
### Interpretation
The data suggests that the choice of reinforcement learning algorithm and synchronization strategy significantly impacts performance. The REC-OneSide-NoIS (0.6, 2.0) algorithm appears to be the most robust, consistently achieving high evaluation accuracy and training reward across different synchronization conditions. REINFORCE, while showing initial promise, is highly susceptible to performance degradation, particularly in the "offline" setting, indicating potential instability or sensitivity to the environment. The synchronization interval and offset also play a crucial role, as evidenced by the varying performance of the algorithms under different settings. The "offline" setting seems to present a more challenging scenario for REINFORCE, possibly due to the lack of real-time updates or feedback.
DECODING INTELLIGENCE...