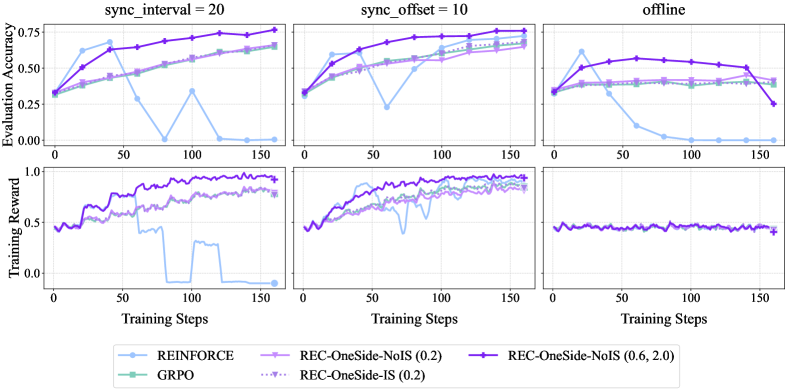
## Chart: Training Performance Comparison
### Overview
The image presents a comparison of training performance for different reinforcement learning algorithms under varying synchronization conditions. It consists of six line charts arranged in a 2x3 grid. The top row displays "Evaluation Accuracy" versus "Training Steps", while the bottom row shows "Training Reward" versus "Training Steps". The charts are grouped by "sync_interval" and "sync_offset" settings, with the final column representing an "offline" condition.
### Components/Axes
* **X-axis:** "Training Steps" (Scale: 0 to 150, increments of 25)
* **Y-axis (Top Row):** "Evaluation Accuracy" (Scale: 0.2 to 0.8, increments of 0.1)
* **Y-axis (Bottom Row):** "Training Reward" (Scale: 0.0 to 1.0, increments of 0.1)
* **Titles (Columns):**
* "sync\_interval = 20"
* "sync\_offset = 10"
* "offline"
* **Legend:** Located at the bottom-center of the image.
* REINFORCE (Light Blue Solid Line)
* GRPO (Light Green Solid Line)
* REC-OneSide-NoIS (0.2) (Light Purple Solid Line)
* REC-OneSide-IS (0.2) (Light Purple Dotted Line)
* REC-OneSide-NoIS (0.6, 2.0) (Dark Purple Solid Line)
* REC-OneSide-IS (0.6, 2.0) (Dark Purple Dotted Line)
### Detailed Analysis or Content Details
**Column 1: sync\_interval = 20**
* **Evaluation Accuracy:**
* REINFORCE: Starts at approximately 0.3, fluctuates significantly, reaching a peak of around 0.6 at step 75, then declines to approximately 0.45 by step 150.
* GRPO: Starts at approximately 0.3, increases steadily to around 0.65 by step 150.
* REC-OneSide-NoIS (0.2): Starts at approximately 0.4, increases steadily to around 0.7 by step 150.
* REC-OneSide-IS (0.2): Starts at approximately 0.4, increases steadily to around 0.7 by step 150.
* REC-OneSide-NoIS (0.6, 2.0): Starts at approximately 0.35, increases steadily to around 0.7 by step 150.
* REC-OneSide-IS (0.6, 2.0): Starts at approximately 0.35, increases steadily to around 0.7 by step 150.
* **Training Reward:**
* REINFORCE: Fluctuates around 0.6, with some dips below 0.5.
* GRPO: Starts around 0.5, drops to approximately 0.2 at step 25, then recovers to around 0.6 by step 150.
* REC-OneSide-NoIS (0.2): Relatively stable around 0.7.
* REC-OneSide-IS (0.2): Relatively stable around 0.7.
* REC-OneSide-NoIS (0.6, 2.0): Relatively stable around 0.7.
* REC-OneSide-IS (0.6, 2.0): Relatively stable around 0.7.
**Column 2: sync\_offset = 10**
* **Evaluation Accuracy:**
* REINFORCE: Starts at approximately 0.3, increases to around 0.65 by step 50, then fluctuates between 0.5 and 0.7.
* GRPO: Starts at approximately 0.3, increases steadily to around 0.7 by step 150.
* REC-OneSide-NoIS (0.2): Starts at approximately 0.4, increases steadily to around 0.75 by step 150.
* REC-OneSide-IS (0.2): Starts at approximately 0.4, increases steadily to around 0.75 by step 150.
* REC-OneSide-NoIS (0.6, 2.0): Starts at approximately 0.35, increases steadily to around 0.75 by step 150.
* REC-OneSide-IS (0.6, 2.0): Starts at approximately 0.35, increases steadily to around 0.75 by step 150.
* **Training Reward:**
* REINFORCE: Fluctuates around 0.6, with some dips below 0.5.
* GRPO: Starts around 0.5, drops to approximately 0.2 at step 25, then recovers to around 0.6 by step 150.
* REC-OneSide-NoIS (0.2): Relatively stable around 0.7.
* REC-OneSide-IS (0.2): Relatively stable around 0.7.
* REC-OneSide-NoIS (0.6, 2.0): Relatively stable around 0.7.
* REC-OneSide-IS (0.6, 2.0): Relatively stable around 0.7.
**Column 3: offline**
* **Evaluation Accuracy:**
* REINFORCE: Starts at approximately 0.4, declines steadily to around 0.3 by step 150.
* GRPO: Starts at approximately 0.4, declines steadily to around 0.3 by step 150.
* REC-OneSide-NoIS (0.2): Remains relatively stable around 0.6.
* REC-OneSide-IS (0.2): Remains relatively stable around 0.6.
* REC-OneSide-NoIS (0.6, 2.0): Remains relatively stable around 0.6.
* REC-OneSide-IS (0.6, 2.0): Remains relatively stable around 0.6.
* **Training Reward:**
* REINFORCE: Remains relatively stable around 0.5.
* GRPO: Remains relatively stable around 0.5.
* REC-OneSide-NoIS (0.2): Remains relatively stable around 0.7.
* REC-OneSide-IS (0.2): Remains relatively stable around 0.7.
* REC-OneSide-NoIS (0.6, 2.0): Remains relatively stable around 0.7.
* REC-OneSide-IS (0.6, 2.0): Remains relatively stable around 0.7.
### Key Observations
* The "REC-OneSide" algorithms consistently outperform REINFORCE and GRPO in terms of evaluation accuracy, especially in the "sync\_interval = 20" and "sync\_offset = 10" conditions.
* GRPO exhibits a significant dip in training reward around step 25 in both the "sync\_interval = 20" and "sync\_offset = 10" conditions.
* REINFORCE shows high variability in evaluation accuracy, particularly in the "sync\_interval = 20" condition.
* In the "offline" condition, REINFORCE and GRPO experience a decline in evaluation accuracy, while the "REC-OneSide" algorithms maintain relatively stable performance.
### Interpretation
The data suggests that the "REC-OneSide" algorithms are more robust and effective for training reinforcement learning agents compared to REINFORCE and GRPO, particularly when synchronization is enabled ("sync\_interval = 20" and "sync\_offset = 10"). The consistent performance of "REC-OneSide" in the "offline" condition indicates that these algorithms are less reliant on real-time interaction and can still achieve good results without synchronization. The dip in GRPO's training reward suggests a potential instability or learning challenge during the initial training phase. The variability in REINFORCE's evaluation accuracy highlights its sensitivity to training conditions. Overall, the results indicate that the "REC-OneSide" algorithms offer a more stable and reliable approach to reinforcement learning training.