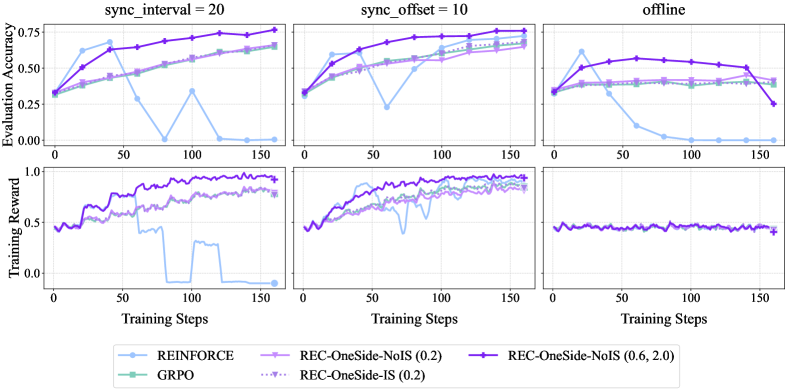
## Line Graphs: Algorithm Performance Comparison Across Training Steps
### Overview
The image contains six line graphs comparing the performance of reinforcement learning algorithms (REINFORCE, REC-OneSide-NoIS, REC-OneSide-IS, GRPO) across three scenarios: `sync_interval=20`, `sync_offset=10`, and `offline`. Each graph tracks **Evaluation Accuracy** (top row) and **Training Reward** (bottom row) over 150 training steps. Key trends include algorithm-specific performance variations under different synchronization settings.
---
### Components/Axes
1. **X-Axis**: Training Steps (0–150, increments of 50)
2. **Y-Axes**:
- Top Row: Evaluation Accuracy (0.0–0.8)
- Bottom Row: Training Reward (0.0–1.0)
3. **Legends**:
- **Blue**: REINFORCE
- **Purple**: REC-OneSide-NoIS (0.2)
- **Green**: GRPO
- **Dotted Purple**: REC-OneSide-IS (0.2)
- **Solid Purple**: REC-OneSide-NoIS (0.6, 2.0)
4. **Graph Labels**:
- Top Row: `sync_interval=20`, `sync_offset=10`, `offline`
- Bottom Row: Corresponding Training Reward graphs
---
### Detailed Analysis
#### Top Row (Evaluation Accuracy)
1. **`sync_interval=20`**:
- **REINFORCE (Blue)**: Starts at ~0.3, dips to ~0.1 at 50 steps, then recovers to ~0.5 by 150 steps.
- **REC-OneSide-NoIS (0.2) (Purple)**: Steady increase from ~0.3 to ~0.7.
- **GRPO (Green)**: Gradual rise from ~0.3 to ~0.6.
- **REC-OneSide-IS (0.2) (Dotted Purple)**: Consistent growth from ~0.3 to ~0.7.
2. **`sync_offset=10`**:
- **REINFORCE (Blue)**: Sharp drop to ~0.2 at 50 steps, recovers to ~0.5 by 150 steps.
- **REC-OneSide-NoIS (0.2) (Purple)**: Stable increase from ~0.3 to ~0.6.
- **GRPO (Green)**: Flat line at ~0.5.
- **REC-OneSide-IS (0.2) (Dotted Purple)**: Slight upward trend from ~0.4 to ~0.6.
3. **`offline`**:
- **REINFORCE (Blue)**: Drops to ~0.1 at 50 steps, remains flat.
- **REC-OneSide-NoIS (0.2) (Purple)**: Stable at ~0.5.
- **GRPO (Green)**: Flat at ~0.4.
- **REC-OneSide-IS (0.2) (Dotted Purple)**: Slight decline from ~0.5 to ~0.4.
#### Bottom Row (Training Reward)
1. **`sync_interval=20`**:
- **REINFORCE (Blue)**: Peaks at ~0.7, crashes to ~0.0 at 50 steps, then recovers to ~0.5.
- **REC-OneSide-NoIS (0.2) (Purple)**: Stable ~0.5–0.6.
- **GRPO (Green)**: Gradual rise from ~0.4 to ~0.6.
- **REC-OneSide-IS (0.2) (Dotted Purple)**: Stable ~0.5–0.6.
2. **`sync_offset=10`**:
- **REINFORCE (Blue)**: Peaks at ~0.7, drops to ~0.2 at 50 steps, recovers to ~0.5.
- **REC-OneSide-NoIS (0.2) (Purple)**: Stable ~0.5–0.6.
- **GRPO (Green)**: Flat at ~0.5.
- **REC-OneSide-IS (0.2) (Dotted Purple)**: Slight increase from ~0.5 to ~0.6.
3. **`offline`**:
- **REINFORCE (Blue)**: Peaks at ~0.7, drops to ~0.1 at 50 steps, remains flat.
- **REC-OneSide-NoIS (0.2) (Purple)**: Stable ~0.4–0.5.
- **GRPO (Green)**: Flat at ~0.4.
- **REC-OneSide-IS (0.2) (Dotted Purple)**: Stable ~0.4–0.5.
---
### Key Observations
1. **REINFORCE Instability**:
- Consistently underperforms in evaluation accuracy and training reward under synchronization settings (`sync_interval=20`, `sync_offset=10`).
- Training reward crashes to near-zero at 50 steps in all scenarios, suggesting sensitivity to hyperparameters or environment settings.
2. **REC-OneSide-NoIS (0.2) Robustness**:
- Maintains stable evaluation accuracy (~0.5–0.7) and training reward (~0.5–0.6) across all scenarios.
3. **GRPO Performance**:
- Evaluation accuracy plateaus at ~0.5–0.6 in synchronization scenarios but underperforms in `offline` (~0.4).
4. **REC-OneSide-IS (0.2) Consistency**:
- Shows steady improvement in evaluation accuracy and stable training reward, outperforming GRPO in synchronization settings.
5. **Offline Scenario**:
- All algorithms exhibit reduced performance compared to synchronization settings, with REINFORCE being the most affected.
---
### Interpretation
The data suggests that **REINFORCE** struggles with synchronization-dependent tasks, likely due to its high variance in gradient estimation. In contrast, **REC-OneSide-NoIS (0.2)** and **REC-OneSide-IS (0.2)** demonstrate robustness, maintaining performance across scenarios. The `offline` setting degrades performance for all algorithms, highlighting the importance of synchronization in training stability. GRPO’s flat performance in `offline` may indicate limitations in handling non-synchronized environments. The training reward crashes for REINFORCE suggest it requires careful tuning to avoid instability, while REC variants balance exploration and exploitation more effectively.