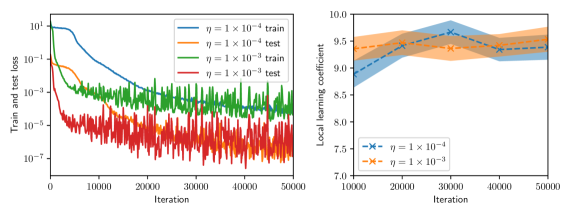
## Chart Type: Combined Line Charts
### Overview
The image contains two line charts side-by-side. The left chart displays "Train and test loss" on a logarithmic scale against "Iteration". It shows four data series representing training and testing loss for two different learning rates (η = 1 x 10^-4 and η = 1 x 10^-3). The right chart displays "Local learning coefficient" against "Iteration" for the same two learning rates, with shaded regions indicating variability.
### Components/Axes
**Left Chart:**
* **Y-axis:** "Train and test loss" (logarithmic scale). Axis markers: 10^-7, 10^-5, 10^-3, 10^-1, 10^1.
* **X-axis:** "Iteration". Axis markers: 0, 10000, 20000, 30000, 40000, 50000.
* **Legend (top-right):**
* Blue: "η = 1 x 10^-4 train"
* Orange: "η = 1 x 10^-4 test"
* Green: "η = 1 x 10^-3 train"
* Red: "η = 1 x 10^-3 test"
**Right Chart:**
* **Y-axis:** "Local learning coefficient". Axis markers: 7.0, 7.5, 8.0, 8.5, 9.0, 9.5, 10.0.
* **X-axis:** "Iteration". Axis markers: 10000, 20000, 30000, 40000, 50000.
* **Legend (bottom-left):**
* Blue with 'x' markers: "η = 1 x 10^-4"
* Orange with 'x' markers: "η = 1 x 10^-3"
### Detailed Analysis
**Left Chart (Train and test loss):**
* **η = 1 x 10^-4 train (Blue):** Starts at approximately 10^1, decreases rapidly until around iteration 10000, then decreases more gradually, reaching approximately 10^-3 at iteration 50000.
* **η = 1 x 10^-4 test (Orange):** Starts at approximately 10^-1, decreases rapidly until around iteration 10000, then remains relatively constant around 10^-5.
* **η = 1 x 10^-3 train (Green):** Starts at approximately 10^-1, decreases rapidly until around iteration 10000, then fluctuates around 10^-3.
* **η = 1 x 10^-3 test (Red):** Starts around 10^-4, fluctuates significantly between 10^-5 and 10^-7.
**Right Chart (Local learning coefficient):**
* **η = 1 x 10^-4 (Blue):** Starts at approximately 8.9 at iteration 10000, increases to approximately 9.7 at iteration 30000, then decreases slightly to approximately 9.4 at iteration 50000. The shaded region indicates a variability of approximately +/- 0.3.
* **η = 1 x 10^-3 (Orange):** Starts at approximately 9.4 at iteration 10000, increases slightly to approximately 9.4 at iteration 20000, then decreases slightly to approximately 9.4 at iteration 50000. The shaded region indicates a variability of approximately +/- 0.3.
### Key Observations
* In the left chart, the training loss decreases more consistently than the testing loss, especially for η = 1 x 10^-3.
* The testing loss for η = 1 x 10^-3 fluctuates significantly, suggesting potential overfitting.
* In the right chart, the local learning coefficient for η = 1 x 10^-3 is consistently higher than for η = 1 x 10^-4.
* The variability in the local learning coefficient is similar for both learning rates.
### Interpretation
The charts suggest that a learning rate of η = 1 x 10^-4 results in more stable training and testing loss compared to η = 1 x 10^-3. The higher learning rate (η = 1 x 10^-3) leads to significant fluctuations in the testing loss, indicating potential overfitting. The local learning coefficient is higher for η = 1 x 10^-3, which might contribute to the observed instability. The data suggests that a lower learning rate might be preferable for this particular model and dataset to achieve better generalization performance.