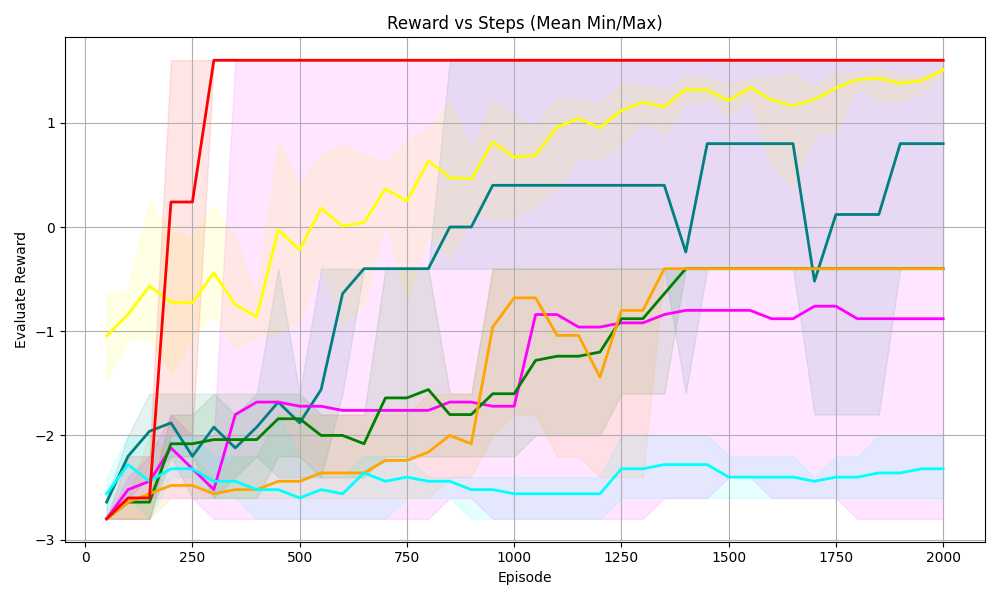
## Line Chart: Reward vs Steps (Mean Min/Max)
### Overview
The chart visualizes the evaluation reward performance of six reinforcement learning algorithms (DQN, A3C, PPO, SAC, DDPG, TRPO) across 2000 episodes. Each line represents the mean reward trajectory, with shaded areas indicating the minimum and maximum reward bounds (likely confidence intervals or variability ranges).
### Components/Axes
- **X-axis**: "Episode" (0 to 2000, increments of 250)
- **Y-axis**: "Evaluation Reward" (-3 to 1, increments of 1)
- **Legend**: Located on the right, mapping colors to algorithms:
- Red: DQN
- Yellow: A3C
- Green: PPO
- Blue: SAC
- Cyan: DDPG
- Magenta: TRPO
- **Shaded Areas**: Envelopes around each line, representing min/max reward bounds.
### Detailed Analysis
1. **DQN (Red)**:
- Starts at -3, spikes to ~1.5 by episode 100, then stabilizes near 1.5.
- Shaded area shows high variability early on, narrowing after episode 100.
2. **A3C (Yellow)**:
- Begins at -1, steadily increases to ~1.5 by episode 2000.
- Shaded area remains relatively narrow, indicating consistent performance.
3. **PPO (Green)**:
- Starts at -2, rises to ~0.5 by episode 2000.
- Shaded area widens initially, then stabilizes.
4. **SAC (Blue)**:
- Begins at -2.5, jumps to ~0.5 around episode 1000, then fluctuates between -0.5 and 0.5.
- Shaded area shows significant variability, especially after episode 1000.
5. **DDPG (Cyan)**:
- Starts at -3, rises to ~0.5 by episode 1500, then plateaus.
- Shaded area narrows after episode 1000.
6. **TRPO (Magenta)**:
- Starts at -3, gradually increases to ~-0.5 by episode 2000.
- Shaded area remains wide throughout, indicating persistent variability.
### Key Observations
- **DQN** achieves the highest peak reward early but plateaus, suggesting limited long-term improvement.
- **A3C** and **SAC** demonstrate the most consistent and highest long-term performance.
- **TRPO** shows the slowest improvement, remaining near -0.5 by episode 2000.
- **DDPG** and **PPO** exhibit moderate performance, with DDPG having sharper early gains.
- Shaded areas reveal that **SAC** and **TRPO** have the highest variability in rewards.
### Interpretation
The data highlights trade-offs between early performance and long-term stability. **A3C** and **SAC** outperform others in sustained reward, while **DQN** excels initially but stagnates. **TRPO**'s wide shaded area suggests unreliable performance, possibly due to high exploration or instability. The chart underscores the importance of algorithm choice based on task requirements: rapid early gains (DQN) vs. consistent long-term improvement (A3C/SAC). Variability in shaded areas may reflect environmental sensitivity or hyperparameter tuning challenges.